
![www.vmgcyvh.cn═ž▓ĮERP|ERPŽĄĮy(t©»ng)|ERP▄ø╝■|ERP╣▄└ĒŽĄĮy(t©»ng)▄ø╝■|├Ō┘MERPŽĄĮy(t©»ng)|├Ō┘MERP▄ø╝■|├Ō┘M▀MõN┤µ▄ø╝■|├Ō┘Mé}Äņ╣▄└Ē▄ø╝■|├Ō┘MŽ┬▌dīŻśI(y©©)┘YėŹŠW(w©Żng)-öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²](http://www.vmgcyvh.cn/images/c_newscenter6.jpg)


▒Š╬─üĒūįöy│╠╝╝ągųąą─╗∙ĄAśI(y©©)äščą░l(f©Ī)▓┐Ą─ĪČæ¬ė├╝▄śŗ─∙śäĪĘŽĄ┴ąĘųŽĒĪŻō■(j©┤)╗∙ĄAśI(y©©)äščą░l(f©Ī)▓┐žōž¤╚╦└ŅąĪ┴ųĮķĮBŻ¼╗ź┬ō(li©ón)ŠW(w©Żng)Č■┤╬Ė’├³Ą─ęŲäė╗ź┬ō(li©ón)ŠW(w©Żng)Ģr┤·Ż¼╚ń║╬╬³ę²ė├æ¶Īó┴¶ūĪė├æ¶▓ó╔Ņ╚ļ═┌Š“ė├æ¶ārųĄŻ¼į┌╝ż┴ęĄ─ĖéĀÄųą├ōĘfČ°│÷Ż¼╩ŪĖ„┤¾ļŖ╔╠Ą─ųžę¬šnŅ}ĪŻ═©▀^Ė„ŅÉ┤¾öĄ(sh©┤)ō■(j©┤)ī”ė├æ¶▀MąąčąŠ┐Ż¼ęįöĄ(sh©┤)ō■(j©┤)“īäė«aŲĘ╩ŪĮŌøQ▀@éĆšnŅ}Ą─ų„ę¬╩ųČ╬Ż¼öy│╠Ą─┤¾öĄ(sh©┤)ō■(j©┤)łFĻĀę▓ė╔┤╦æ¬▀\Č°╔·Ż╗Įø▀^Äū─ĻĄ─┼¼┴”Ż¼┤¾öĄ(sh©┤)ō■(j©┤)Ą─ŽÓĻP╝╝ąg×ķśI(y©©)äšÄ¦üĒ┴╦¾@╚╦Ą─╠ß╔²┼cÄ═ų·ĪŻęį╗∙ĄA┤¾öĄ(sh©┤)ō■(j©┤)Ą─ė├æ¶ęŌłDĘ■äš×ķ└²Ż¼═©▀^īóÅVĖµ║═Ö┌╬╗Ą─“Ū¦╚╦ę╗├µ”ūā?y©Łu)?ldquo;Ū¦╚╦Ū¦├µ”Ż¼į┌╠ß╔²ė├æ¶▒ŃĮ▌ąįŻ¼┐╔ė├ąįŻ¼ĮĄĄ═┘M┴”Č╚Ą─═¼ĢrŻ¼Ųõ▐D╗»┬╩ę▓Ą├ĄĮ┴╦öĄ(sh©┤)▒ČĄ─╠ß╔²Ż¼¾w¼F(xi©żn)┴╦┤¾öĄ(sh©┤)ō■(j©┤)Ę■䚥─šµš²ārųĄĪŻ
į┌└ŅąĪ┴ų┐┤üĒŻ¼┤¾öĄ(sh©┤)ō■(j©┤)╩Ū╗ź┬ō(li©ón)ŠW(w©Żng)ąąśI(y©©)░l(f©Ī)š╣Ą─┌ģä▌Ż¼╗ź┬ō(li©ón)ŠW(w©Żng)Ą─Å─śI(y©©)╚╦åTąĶę¬Ė▀Č╚ĻPūó┤¾öĄ(sh©┤)ō■(j©┤)ŽÓĻPĄ─╝╝ąg╝░æ¬ė├Ż¼ę▓ŽŻ═¹═©▀^▀@ę╗ŽĄ┴ą┤¾öĄ(sh©┤)ō■(j©┤)ŽÓĻPĄ─ųvū∙Ż¼ūīĖ„╬╗═¼īWėą╦∙╩š½@ĪŻ
╩ūł÷ĪČæ¬ė├╝▄śŗ─∙┼═ĪĘĘųŽĒüĒūį╗∙ĄAśI(y©©)äščą░l(f©Ī)▓┐Ą─ČŁõJŻ¼░³└©śI(y©©)äšĖ▀╦┘░l(f©Ī)š╣ĦüĒĄ─æ¬ė├╝▄śŗ╠¶æ(zh©żn)Īóæ¬ī”╠¶æ(zh©żn)Ą─╝▄śŗ─∙┼═Īóæ¬ė├ŽĄĮy(t©»ng)š¹¾w╝▄śŗ║══Ų╦]ŽĄĮy(t©»ng)░Ė└²Ą╚╦─éĆ▓┐ĘųĪŻ
![öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²](http://www.vmgcyvh.cn/upfile/eweb/2016827181032613.jpg)
ę╗ĪóśI(y©©)äšĖ▀╦┘░l(f©Ī)š╣ĦüĒĄ─æ¬ė├╝▄śŗ╠¶æ(zh©żn)
╣½╦ŠśI(y©©)äšĖ▀╦┘░l(f©Ī)š╣ĦüĒ──ą®ų„ꬥ─ūā╗»Ż¼ęį╝░Įo╬ęéāĄ─ŽĄĮy(t©»ng)ĦüĒ┴╦──ą®╠¶æ(zh©żn)Ż┐
śI(y©©)äšąĶŪ¾Ą─╝▒╦┘į÷ķLŻ¼įL墚łŪ¾Ą─▓ó░l(f©Ī)┴┐╝żį÷Ż¼2016─Ļ1į┬Ę▌ęįüĒŻ¼śI(y©©)äš▓┐ķTĄ─Ę■äš╚šŠ∙šłŪ¾┴┐╝żį÷┴╦5.5▒ČĪŻ
śI(y©©)äš▀ē▌ŗ╚šęµÅ═ļs╗»Ż¼╗∙ĄAśI(y©©)äščą░l(f©Ī)▓┐ąĶę¬ų¦ō╬ŲOTAöĄ(sh©┤)╩«éĆśI(y©©)䚊Ư¼śI(y©©)äš▀ē▌ŗ╚š┌ģÅ═ļs║═Ę▒ČÓĪŻ
śI(y©©)äšöĄ(sh©┤)ō■(j©┤)į┤ČÓśė╗»Ż¼«Éśŗ╗»Ż¼Įė╚ļĄ─śI(y©©)䚊ĆĪó║Žū„╣½╦ŠĄ─öĄ(sh©┤)ō■(j©┤)į┤įĮüĒįĮČÓŻ╗Įė╚ļĄ─öĄ(sh©┤)ō■(j©┤)ĮYśŗė╔ęįŪ░Ą─öĄ(sh©┤)ō■(j©┤)ÄņĮYśŗ╗»öĄ(sh©┤)ō■(j©┤)š¹║Ž▐D×ķHive▒ĒĪóįušō╬─▒ŠöĄ(sh©┤)ō■(j©┤)Īó╚šųŠöĄ(sh©┤)ō■(j©┤)Īó╠ņÜŌöĄ(sh©┤)ō■(j©┤)ĪóŠW(w©Żng)ĒōöĄ(sh©┤)ō■(j©┤)Ą╚ČÓį¬╗»«ÉśŗöĄ(sh©┤)ō■(j©┤)š¹║ŽĪŻ
śI(y©©)䚥─Ė▀╦┘░l(f©Ī)š╣║═Ą³┤·Ż¼▓┐ķTę╗ų▒ęįūĘŪ¾ęįūŅ╔┘Ą─ķ_░l(f©Ī)╚╦┴”Ż¼ęį╝▄śŗ║═ŽĄĮy(t©»ng)Ą─╝╝ągā×(y©Łu)╗»Ż¼ų¦ō╬Ųöy│╠Ė„śI(y©©)䚊ĆĖ▀╦┘░l(f©Ī)š╣║═Ą³┤·Ą─ąĶę¬ĪŻ
į┌▀@ĘNą┬ą╬ä▌Ž┬Ż¼é„Įy(t©»ng)æ¬ė├╝▄śŗ▓╗Ą├▓╗ūāŻ¼ū÷×ķ╣ż│╠Ĥę▓▒ž╚╗ę¬ūį╬ę─∙śäŻ¼Ė─×ķ┤¾öĄ(sh©┤)ō■(j©┤)╝░ą┬Ą─Ė▀▓ó░l(f©Ī)╝▄śŗŻ¼üĒæ¬ī”śI(y©©)äšąĶŪ¾╝żį÷╝░Ė▀╦┘Ą³┤·Ą─ąĶę¬ĪŻėŗ╦ŃĘųīėĘųĮŌĪó╚źSQLĪó╚źöĄ(sh©┤)ō■(j©┤)Äņ╗»Īó─ŻēK╗»▓ĮŌĄ─ŽÓĻP╝╝Ė─╣żū„ęčĮø┐╠▓╗╚▌ŠÅĪŻ
![öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²](http://www.vmgcyvh.cn/upfile/eweb/2016827181032250.jpg)
ęįė├æ¶ęŌłD(AI ³cĮš╚)Ą─éĆąį╗»Ę■äš×ķ└²Ż¼ ├µī”BUśI(y©©)䚊ƥ─╚½├µų¦│ųĄ─Ų╚ŪąąĶ꬯¼Ųõæ¬ė├╝▄śŗ▒žĒÜĮŌøQ╚ńŽ┬╝╝ągļy³cŻ║
Ė▀įLå¢▓ó░l(f©Ī)Ż║├┐╠ņĮ³ā|┤╬Ą─įL墚łŪ¾Ż╗
öĄ(sh©┤)ō■(j©┤)┴┐┤¾Ż║├┐╠ņTB╝ēĄ─į÷┴┐öĄ(sh©┤)ō■(j©┤)Ż¼Į³░┘ā|ŚlĄ─ė├æ¶öĄ(sh©┤)ō■(j©┤)Ż¼╔Ž░┘╚fĄ─«aŲĘöĄ(sh©┤)ō■(j©┤)Ż╗
śI(y©©)äš▀ē▌ŗÅ═ļsŻ║Å═ļséĆąį╗»╦ŃĘ©║═LBS╦ŃĘ©Ż╗└²╚ńŻ║ØMūŃę╗éĆÅ═ļsė├涚łŪ¾ąĶę¬┤¾┴┐ėŗ╦Ń║═30┤╬ū¾ėęĄ─SQLöĄ(sh©┤)ō■(j©┤)▓ķįāŻ¼Ę■äščėĢrįĮüĒįĮķLŻ╗
Ė▀╦┘Ą³┤·╔ŽŠĆŻ║├µī”OTAČÓśI(y©©)䚊ƥ─éĆąį╗»ĪóCross-salingĪóUp-salingĪóąĶØMūŃ╠ß╔²▐D╗»┬╩Ą─Ų╚ŪąąĶŪ¾Ż¼Ą³┤·Ö┌╬╗╗“ł÷Š░ę¬┐ņ╦┘Ż¼═¼Ģr£p╔┘čą░l(f©Ī)│╔▒ŠĪŻ
Č■Īóæ¬ī”╠¶æ(zh©żn)Ą─╝▄śŗ─∙┼═
├µī”▀@ą®╠¶æ(zh©żn)Ż¼╬ęéāĄ─æ¬ė├ŽĄĮy(t©»ng)╝▄śŗæ¬įō╚ń║╬─∙┼═Ż┐ų„ę¬Ęų╚ńŽ┬╚²┤¾ĘĮ├µŽĄĮy(t©»ng)įöĮŌŻ║
┤µā”Ą──∙┼═Ż¼▀@ę╗³cī”ė┌š¹éĆŽĄĮy(t©»ng)Ą─═╠═┬┴┐║═▓ó░l(f©Ī)┴┐Ą─╠ß╔²ŲĄĮūŅĻPµIĄ─ū„ė├Ż¼ąĶę¬ĮY║ŽöĄ(sh©┤)ō■(j©┤)┤µā”─Żą═║═Š▀¾wæ¬ė├Ą─ł÷Š░ĪŻ
ėŗ╦ŃĄ──∙┼═Ż¼┐╔ęįÅ─ÖMŽ“║═┐vŽ“┐╝æ]Ż║ÖMŽ“ų„ę¬╩Ūį÷╝ė▓ó░l(f©Ī)Č╚Ż¼╩ūŽ╚ŽļĄĮĄ─╩ŪĘų▓╝╩ĮĪŻ┐vŽ“▓ĘųŠ═╩Ūę¬Ū¾╬ęéāšęĄĮėŗ╦ŃĄ─ĮY║Ž³cÅ─Č°▀MąąĘųīėŻ¼ßśī”▓╗═¼Ą─īė┤╬▀xō±▓╗═¼Ą─ėŗ╦ŃĄž³cĪŻ╚╗║¾į┘īóĖ„īė┤╬ėŗ╦Ń═Ļ║¾Ą─ĮY╣¹ŽÓĮY║ŽŻ¼▒M┐╔─▄ūŅ┤¾╗»ŽĄĮy(t©»ng)š¹¾wĄ─╠Ä└Ē─▄┴”ĪŻ
śI(y©©)äšīė╝▄śŗĄ──∙┼═Ż¼ę¬Ū¾ŽĄĮy(t©»ng)Ą─┴╝║├Ą──ŻēK╗»įOėŗŻ¼ŪÕ│■Ą─Č©┴x─ŻēKĄ─▀ģĮńŻ¼─ŻēKūį╔²╝ē║═┐╔┼õų├╗»ĪŻ
╚²Īóæ¬ė├ŽĄĮy(t©»ng)Ą─š¹¾w╝▄śŗ
šJūRĄĮąĶę¬æ¬ī”Ą─╠¶æ(zh©żn)Ż¼╬ęéāæ¬įō╚ń║╬įOėŗ╬ęéāĄ─ŽĄĮy(t©»ng)─žŻ¼Ž┬├µīó╚½├µĄ─ĮķĮBŽ┬╬ęéāĄ─æ¬ė├ŽĄĮy(t©»ng)š¹¾w╝▄śŗĪŻ
Ž┬łDŠ═╩Ū╬ęéāæ¬ė├ŽĄĮy(t©»ng)š¹¾w╝▄śŗęį╝░ŽĄĮy(t©»ng)īė┤╬Ą──ŻēKśŗ│╔ĪŻ
![öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²](http://www.vmgcyvh.cn/upfile/eweb/2016827181033690.jpg)
öĄ(sh©┤)ō■(j©┤)į┤▓┐ĘųŻ¼Hermes╩Ūöy│╠┐“╝▄▓┐ķT╠ß╣®Ą─Ž¹ŽóĻĀ┴ąŻ¼╗∙ė┌Kafka║═MySQLū÷×ķĄūīėīŹ¼F(xi©żn)Ą─ĘŌčbŻ¼æ¬ė├ė┌ŽĄĮy(t©»ng)ķgīŹĢröĄ(sh©┤)ō■(j©┤)é„▌öĮ╗╗ź═©Ą└ĪŻHive║═HDFS╩Ūöy│╠║Ż┴┐öĄ(sh©┤)ō■(j©┤)Ą─ų„ę¬┤µā”Ż¼ā╔š▀üĒūįHadoop╔·æB(t©żi)¾wŽĄĪŻHadoop┤¾╝ęęčĮø║▄╩ņŽżŻ¼╚ń╣¹▓╗╩ņŽżĄ─═¼īWų╗ę¬ų¬Ą└Hadoopų„ę¬ė├ė┌┤¾öĄ(sh©┤)ō■(j©┤)┴┐┤µā”║═▓óąąėŗ╦Ń┼·╠Ä└Ē╣żū„ĪŻ
Hive╩Ū╗∙ė┌HadoopŲĮ┼_Ą─öĄ(sh©┤)ō■(j©┤)é}ÄņŻ¼čžė├┴╦ĻPŽĄą═öĄ(sh©┤)ō■(j©┤)ÄņĄ─║▄ČÓĖ┼─ŅĪŻ▒╚╚ńšföĄ(sh©┤)ō■(j©┤)Äņ║═▒ĒŻ¼▀Ćėąę╗╠ūĮ³╦Ųė┌SQLĄ─▓ķįāĮė┐┌Ą─ų¦│ųŻ¼į┌Hive└’Įąū÷HQLŻ¼Ą½╩ŪŲõĄūīėĄ─īŹ¼F(xi©żn)╝Ü╣Ø(ji©”)║═ĻPŽĄą═öĄ(sh©┤)ō■(j©┤)Äņ═Ļ╚½▓╗ę╗śėŻ¼HiveĄūīė╦∙ėąĄ─ėŗ╦ŃČ╝╩Ū╗∙ė┌MRüĒ═Ļ│╔Ż¼╬ęéāĄ─öĄ(sh©┤)ō■(j©┤)╣ż│╠Ĥ90%Č╝öĄ(sh©┤)ō■(j©┤)╠Ä└Ē╣żū„Č╝╗∙ė┌╦³üĒ═Ļ│╔ĪŻ
ļxŠĆ▓┐ĘųŻ¼░³║¼Ą──ŻēKėąMRĪóHiveĪóMahoutĪóSparkQL/MLLibĪŻHive╔Ž├µęčĮøĮķĮB▀^Ż¼Mahout║åå╬└ĒĮŌ╠ß╣®╗∙ė┌HadoopŲĮ┼_▀MąąöĄ(sh©┤)ō■(j©┤)═┌Š“Ą─ę╗ą®ÖCŲ„īW┴ĢĄ─╦ŃĘ©░³ĪŻSparkŅÉ╦Ųhadoopę▓╩Ū╠ß╣®┤¾öĄ(sh©┤)ō■(j©┤)▓óąą┼·┴┐╠Ä└ĒŲĮ┼_Ż¼Ą½╩Ū╦³╩Ū╗∙ė┌ā╚┤µĄ─ĪŻSparkQL ║═Spark MLLib╩Ū╗∙ė┌SparkŲĮ┼_Ą─SQL▓ķįāę²Ūµ║═öĄ(sh©┤)ō■(j©┤)═┌Š“ŽÓĻP╦ŃĘ©┐“╝▄ĪŻ╬ęéāų„ę¬ė├Mahout║═Spark MLLib▀MąąöĄ(sh©┤)ō■(j©┤)═┌Š“╣żū„ĪŻ
š{Č╚ŽĄĮy(t©»ng)zeusŻ¼╩Ū╠įīÜķ_į┤┤¾öĄ(sh©┤)ō■(j©┤)ŲĮ┼_š{Č╚ŽĄĮy(t©»ng)Ż¼ė┌2015─Ļę²▀MĄĮöy│╠Ż¼ų«║¾╬ęéā▀Mąą┴╦ųžśŗ║═╣”─▄╔²╝ēŻ¼ū÷×ķöy│╠┤¾öĄ(sh©┤)ō■(j©┤)ŲĮ┼_Ą─ū„śI(y©©)š{Č╚ŲĮ┼_ĪŻ
Į³ŠĆ▓┐ĘųŻ¼╩Ū╗∙ė┌MuiseüĒīŹ¼F(xi©żn)╬ęéāĄ─Į³īŹĢrĄ─ėŗ╦Ńł÷Š░Ż¼Muise╩Ūę▓╩Ūöy│╠OPS╠ß╣®Ą─īŹĢrėŗ╦Ń┴„╠Ä└ĒŲĮ┼_Ż¼ā╚▓┐╩Ū╗∙ė┌StormīŹ¼F(xi©żn)┼cHERMESŽ¹ŽóĻĀ┴ą┤Ņ┼õŲüĒ╩╣ė├ĪŻ└²╚ńŻ¼╬ęéā╩╣ė├MUSIE═©▀^Ž¹┘MüĒūįŽ¹ŽóĻĀ┴ą└’Ą─ė├æ¶īŹĢrąą×ķŻ¼ėåå╬ėøõøŻ¼ĮY║Ž«ŗŽ±Ą╚ę╗Ų╗∙ĄAöĄ(sh©┤)ō■(j©┤)Ż¼Įøę╗ŽĄ┴ąÅ═ļsĄ─ęÄ(gu©®)ät║═╦ŃĘ©Ż¼īŹĢrĄ─ūRäe│÷ė├æ¶Ą─ąą│╠ęŌłDĪŻ
║¾┼_/ŠĆ╔Žæ¬ė├▓┐ĘųŻ¼MySQLė├ė┌ų¦ō╬║¾┼_ŽĄĮy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)ÄņĪŻElasticSearch╩Ū╗∙ė┌LuceneīŹ¼F(xi©żn)Ą─Ęų▓╝╩Į╦č╦„ę²ŪµŻ¼ė├ė┌╦„ę²ė├涫ŗŽ±Ą─öĄ(sh©┤)ō■(j©┤)Ż¼ų¦│ųļxŠĆŠ½£╩ĀIõNĄ─ė├æ¶║Y▀xŻ¼═¼Ģrų¦│ųŠĆ╔Žæ¬ė├═Ų╦]ŽĄĮy(t©»ng)Ą─▀xŲĘ╣”─▄ĪŻHBase ╗∙ė┌HadoopĄ─HDFS ╔ŽĄ─┴ą┤µā”NoSQLöĄ(sh©┤)ō■(j©┤)ÄņŻ¼ė├ė┌║¾┼_ł¾▒Ē┐╔ęĢ╗»ŽĄĮy(t©»ng)║═ŠĆ╔ŽĘ■䚥─öĄ(sh©┤)ō■(j©┤)┤µā”ĪŻ
▀@└’šf├„ę╗Ž┬Ż¼ į┌ŠĆ║═║¾┼_æ¬ė├╩╣ė├Ą─ElasticSearch║═HBase╝»╚║╩ŪĘųķ_Ą─Ż¼╗ź▓╗ė░ĒæĪŻRedisų¦│ųį┌ŠĆĘ■䚥─Ė▀╦┘ŠÅ┤µŻ¼ė├ė┌ŠÅ┤µĮy(t©»ng)ėŗĘų╬÷│÷üĒĄ─¤ß³cöĄ(sh©┤)ō■(j©┤)ĪŻ
╦─Īó═Ų╦]ŽĄĮy(t©»ng)░Ė└²
ĮķĮB═Ļ╬ęéāæ¬ė├ŽĄĮy(t©»ng)Ą─š¹¾wśŗ│╔Ż¼ĮėŽ┬üĒĘųŽĒ╗∙ė┌▀@╠ūŽĄĮy(t©»ng)╝▄śŗīŹ¼F(xi©żn)Ą─ę╗éĆīŹ└²——öy│╠éĆąį╗»═Ų╦]ŽĄĮy(t©»ng)ĪŻ
═Ų╦]ŽĄĮy(t©»ng)Ą─╝▄śŗłDŻ║
![öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²](http://www.vmgcyvh.cn/upfile/eweb/2016827181033701.jpg)
1Īó┤µā”Ą──∙┼═
1)NoSQL (HBase+Redis)
![öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²](http://www.vmgcyvh.cn/upfile/eweb/2016827181034155.jpg)
╬ęéāų«Ū░┤µā”╩╣ė├Ą─╩ŪMySQLŻ¼ę╗░ŃĻPŽĄą═öĄ(sh©┤)ō■(j©┤)ÄņĢ■ū÷×ķæ¬ė├ŽĄĮy(t©»ng)┤µā”Ą─╩ū▀xĪŻ┤¾╝ęų¬Ą└MySQLĘŪ╔╠śI(y©©)░µī”Ęų▓╝╩Įų¦│ų▓╗ē“Ż¼į┌┤µā”öĄ(sh©┤)ō■(j©┤)┴┐▓╗Ė▀Ż¼▓ķįā┴┐║═ėŗ╦ŃÅ═ļsČ╚▓╗╩Ū║▄┤¾Ą─ŪķørŽ┬Ż¼┐╔ęįØMūŃæ¬ė├ŽĄĮy(t©»ng)Į^┤¾▓┐ĘųĄ─╣”─▄ąĶŪ¾ĪŻ
╬ęéā¼F(xi©żn)ĀŅ╩ŪąĶę¬░▓╚½┤µā”║Ż┴┐Ą─öĄ(sh©┤)ō■(j©┤)Ż¼Ė▀═╠═┬Ż¼▓ó░l(f©Ī)─▄┴”ÅŖŻ¼═¼ĢrļSų°öĄ(sh©┤)ō■(j©┤)┴┐║═šłŪ¾┴┐Ą─┐ņ╦┘į÷╝ėŻ¼─▄ē“═©▀^╝ė╣Ø(ji©”)³cüĒöU╚▌ĪŻ┴Ē═Ō▀ĆąĶę¬ų¦│ų╣╩šŽ▐DęŲŻ¼ūįäė╗ųÅ═Ż¼¤oąĶŅ~═ŌĄ─▀\ŠS│╔▒ŠĪŻŠC╔ŽÄūéĆų„ę¬ę“╦žŻ¼╬ęéā▀Mąą┴╦┤¾┴┐Ą─š{čą║═£yįćŻ¼ūŅĮK╬ęéā▀xė├HBase║═Redisā╔éĆNoSQLöĄ(sh©┤)ō■(j©┤)ÄņüĒ╚Ī┤·ęį═∙╩╣ė├Ą─MySQLĪŻ╬ęéā░čė├æ¶ęŌłDęį╝░═Ų╦]«aŲĘöĄ(sh©┤)ō■(j©┤)ęįKVĄ─ą╬╩Į┤µā”į┌HBaseųąŻ¼╬ęī”▓┘ū„HBase▀Mąąę╗ą®ā×(y©Łu)╗»Ż¼Ųõųą░³└©rowkeyĄ─įOėŗŻ¼ŅAĘų┼õŻ¼öĄ(sh©┤)ō■(j©┤)ē║┐sĄ╚Ż¼═¼Ģrßśī”╬ęéāĄ─╩╣ė├ł÷Š░ī”HBase▒Š╔Ē┼õų├ĘĮ├µĄ─ę▓▀Mąą┴╦š{ā×(y©Łu)ĪŻ─┐Ū░┤µā”Ą─öĄ(sh©┤)ō■(j©┤)┴┐ęčĮø▀_ĄĮTB╝ēäeŻ¼ų¦│ų├┐╠ņŪ¦╚f┤╬šłŪ¾Ż¼═¼Ģr▒ŻūC99%į┌50║┴├ļā╚ĘĄ╗žĪŻ
![öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²](http://www.vmgcyvh.cn/upfile/eweb/2016827181034663.jpg)
Redis║═ČÓöĄ(sh©┤)æ¬ė├ŽĄĮy(t©»ng)╩╣ė├ĘĮ╩Įę╗śėŻ¼ų„ę¬ė├ė┌ŠÅ┤µ¤ß³cöĄ(sh©┤)ō■(j©┤)Ż¼▀@└’Š═▓╗ČÓšf┴╦ĪŻ
![öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²](http://www.vmgcyvh.cn/upfile/eweb/2016827181034401.jpg)
2)╦č╦„ę²Ūµ (ElasticSearch)
![öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²](http://www.vmgcyvh.cn/upfile/eweb/2016827181035425.jpg)
ES╦„ę²Ė„śI(y©©)䚊ƫaŲĘ╠žš„öĄ(sh©┤)ō■(j©┤)Ż¼╠ß╣®╗∙ė┌ė├æ¶Ą─ęŌłD╠žš„║═«aŲĘ╠žš„Å═ļsĄ─ČÓŠSÖz╦„║═┼┼ą“╣”─▄Ż¼«öŪ░╝»╚║ė╔4┼_┤¾ā╚┤µ╬’└ĒÖCŲ„śŗ│╔Ż¼▓╔ė├╚½ā╚┤µ╦„ę²ĪŻī”▒╚─│ę╗éĆÅ═ļsĄ─▓ķįāł÷Š░Ż¼ų«Ū░ė├MySQLīóĮ³ąĶę¬30┤╬▓ķįāŻ¼╩╣ė├ESų╗ąĶę¬ę╗┤╬ĮM║Ž▓ķįāŪęį┌100║┴├ļā╚ĘĄ╗žĪŻ─┐Ū░├┐╠ņŪ¦╚f┤╬╦č╦„Ż¼99%ęį╔Žį┌300║┴├ļęįā╚ĘĄ╗žĪŻ
![öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²](http://www.vmgcyvh.cn/upfile/eweb/2016827181035739.jpg)
2Īóėŗ╦ŃĄ──∙┼═
1)öĄ(sh©┤)ō■(j©┤)į┤Ż¼╬ęéāĄ─öĄ(sh©┤)ō■(j©┤)į┤ĘųĮYśŗ╗»║═░ļĮYśŗ╗»öĄ(sh©┤)ō■(j©┤)ęį╝░ĘŪĮYśŗ╗»öĄ(sh©┤)ō■(j©┤)ĪŻ
![öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²](http://www.vmgcyvh.cn/upfile/eweb/2016827181035455.jpg)
ĮYśŗ╗»öĄ(sh©┤)ō■(j©┤)ų„ę¬╩ŪųĖöy│╠Ė„«aŠĆĄ─«aŲĘŠS▒Ē║═ėåå╬öĄ(sh©┤)ō■(j©┤)Ż¼ėąŠŲĄĻĪóŠ░ŠŲĪółFĻĀė╬ĪóķTŲ▒ĪóŠ░³cĄ╚Ż¼▀Ćėąę╗ą®╗∙ĄAöĄ(sh©┤)ō■(j©┤)Ż¼▒╚╚ń│Ū╩ą▒ĒĪó▄暊Ą╚Ż¼▀@ŅÉöĄ(sh©┤)ō■(j©┤)╗∙▒Š╔ŽČ╝╩ŪT+1Ż¼├┐╠ņĢ■ėą┴„│╠╚źĖ„BUĄ─╔·«a▒Ē└Ł╚ĪöĄ(sh©┤)ō■(j©┤)ĪŻ
░ļĮYśŗ╗»öĄ(sh©┤)ō■(j©┤)╩ŪųĖŻ¼öy│╠ė├æ¶Ą─įLå¢ąą×ķöĄ(sh©┤)ō■(j©┤)Ż¼└²╚ń×gė[Īó╦č╦„ĪóŅAėåĪóĘ┤üĄ╚Ż¼▀@▀ģĒś▒Ń╠ßę╗Ž┬Ż¼▀@ą®öĄ(sh©┤)ō■(j©┤)▀@ą®╩Ūė╔Ū░Č╦▓╔╝»┐“╝▄īŹĢr▓╔╝»Ż¼╚╗║¾Ž┬░l(f©Ī)ĄĮ║¾Č╦Ą─╩š╝»Ę■䚯¼ė╔╩š╝»Ę■äšį┌īæ╚ļĄĮHermesŽ¹ŽóĻĀ┴ąŻ¼ę╗┬ĘĢ■┬õĄžĄĮHadoop╔Ž├µū÷ķLŲ┌┤µā”Ż¼┴Ēę╗┬ĘĮ³ŠĆīė┐╔ęį═©▀^ėåķåHermes┤╦ŅÉöĄ(sh©┤)ō■(j©┤)Topic▀MąąĮ³īŹĢrĄ─ėŗ╦Ń╣żū„ĪŻ
╬ęéā▀Ćė├ĄĮ═Ō▓┐║Žū„Ū■Ą└Ą─öĄ(sh©┤)ō■(j©┤)Ż¼▀Ćėąę╗ą®įušōöĄ(sh©┤)ō■(j©┤)Ż¼įušōī┘ė┌ĘŪĮYśŗ╗»Ą─Ż¼ę▓╩ŪT+1Ė³ą┬ĪŻ
2)ļxŠĆėŗ╦ŃŻ¼ų„ę¬Ęų╚²éĆ╠Ä└ĒļAČ╬ĪŻ
![öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²](http://www.vmgcyvh.cn/upfile/eweb/2016827181036135.jpg)
ŅA╠Ä└ĒļAČ╬Ż¼▀@ēKų„ę¬×ķ║¾└m(x©┤)öĄ(sh©┤)ō■(j©┤)═┌Š“ū÷ę╗ą®öĄ(sh©┤)ō■(j©┤)Ą─£╩éõ╣żū„Ż¼öĄ(sh©┤)ō■(j©┤)╚źųžŻ¼▀^×VŻ¼ī”╚▒╩¦ą┼ŽóĄ─čaūŃĪŻ┼e└²üĒšf▓╔╝»Ž┬üĒĄ─ė├æ¶ąą×ķöĄ(sh©┤)ō■(j©┤)Ż¼╦∙║¼ėąĄ─«aŲĘą┼Žó║▄╔┘Ż¼╬ęéāĢ■╩╣ė├«aŲĘ▒ĒĄ─öĄ(sh©┤)ō■(j©┤)▀Mąąę╗ą®čaūŃŻ¼┤_▒ŻĮo║¾└m(x©┤)Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“╩╣ė├Ģr║“▒M┴┐═Ļš¹Ą─ĪŻ
öĄ(sh©┤)ō■(j©┤)═┌Š“ļAČ╬Ż¼ų„ę¬▀\ė├ę╗ą®│Żė├Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“╦ŃĘ©▀Mąą─Żą═ė¢ŠÜ║══Ų╦]öĄ(sh©┤)ō■(j©┤)Ą─▌ö│÷(ĘųŅÉĪóŠ█ŅÉĪó╗žÜwĪóCFĄ╚)ĪŻ
ĮY╣¹ī¦╚ļļAČ╬Ż¼╬ęéā═©▀^┐╔┼õų├Ą─öĄ(sh©┤)ō■(j©┤)ī¦╚ļ╣żŠ▀īó═Ų╦]öĄ(sh©┤)ō■(j©┤)Ż¼▀Mąąę╗ŽĄ┴ą▐DōQ║¾Ż¼ī¦╚ļĄĮHBaseĪóRedisęį╝░Į©┴óES╦„ę²Ż¼Redis┤µā”Ą─╩ŪĮøĮy(t©»ng)ėŗėŗ╦Ń│÷Ą─¤ß³cöĄ(sh©┤)ō■(j©┤)ĪŻ
3)Į³ŠĆėŗ╦Ń(ė├æ¶ęŌłDĪó«aŲĘŠÅ┤µ)
«öė├æ¶ø]ėą├„┤_Ą──┐Ą─ąįŪķørŽ┬Ż¼║▄ļyšęĄĮØMūŃ┼d╚żĄ─«aŲĘŻ¼╬ęéā▓╗āHąĶę¬┴╦ĮŌė├æ¶Ą─Üv╩Ę┼d╚żŻ¼ė├æ¶īŹĢrąą×ķ╠žš„Ą─│ķ╚Ī║═└ĒĮŌĖ³╝ėųžę¬Ż¼ęį▒Ń┐ņ╦┘Ą─═Ų╦]│÷Ę¹║Žė├涫öŪ░┼d╚żĄ─«aŲĘŻ¼▀@Š═╩Ūė├æ¶ęŌłDĘ■äšąĶę¬īŹ¼F(xi©żn)Ą─╣”─▄ĪŻ
ę╗░ŃüĒšfė├æ¶╠žš„Ęų│╔ā╔┤¾ŅÉŻ║ę╗ĘN╩ŪĘĆ(w©¦n)Č©Ą─╠žš„(ė├涫ŗŽ±)Ż¼╚ńė├æ¶ąįäeĪó│ŻūĪĄžĪóų„Ņ}Ų½║├Ą╚╠žš„Ż╗┴Ēę╗ŅÉ╩ŪĖ∙ō■(j©┤)ė├æ¶ąą×ķėŗ╦Ń½@╚ĪĄ─╠žš„Ż¼╚ńė├æ¶ī”ŠŲĄĻąŪ╝ēĄ─Ų½║├Īó─┐Ą─ĄžŲ½║├ĪóĖ·łFė╬/ūįė╔ąąŲ½║├Ą╚ĪŻ╗∙ė┌Ū░├µ╦∙╩÷Ą─ėŗ╦ŃĄ─╠ž³cŻ¼╬ęéā╩╣ė├Į³į┌ŠĆėŗ╦ŃüĒ½@╚ĪĄ┌Č■ŅÉė├æ¶╠žš„Ż¼š¹¾w┐“łD╚ńŽ┬ĪŻÅ─łDųą┐╔ęį┐┤│÷╦³Ą─▌ö╚ļöĄ(sh©┤)ō■(j©┤)į┤░³└©ā╔┤¾ŅÉŻ║Ą┌ę╗ŅÉ╩ŪīŹĢrĄ─ė├æ¶ąą×ķŻ╗Ą┌Č■ŅÉ╩Ūė├涫ŗŽ±Ż¼Üv╩ĘĮ╗ęūęį╝░ŪķŠ░Ą╚ļxŠĆ─ŻēK╠ß╣®Ą─öĄ(sh©┤)ō■(j©┤)ĪŻĮY║Ž▀@ā╔ŅÉöĄ(sh©┤)ō■(j©┤)Ż¼Įøę╗ą®┴ąÅ═ļsĄ─Į³ŠĆīW┴Ģ╦ŃĘ©║═ęÄ(gu©®)ätę²ŪµŻ¼ėŗ╦ŃĄ├│÷ė├涫öŪ░īŹĢręŌłD┴ą▒Ē┤µā”ĄĮHBase║═RedisųąĪŻ
![öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²](http://www.vmgcyvh.cn/upfile/eweb/2016827181036520.jpg)
Į³ŠĆ┴Ēę╗éĆ╣żū„╩Ū«aŲĘöĄ(sh©┤)ō■(j©┤)ŠÅ┤µŻ¼öy│╠Ą─śI(y©©)䚊Ć║▄ČÓŻ¼Č°╬ęéāĄ─═Ų╦]ŽĄĮy(t©»ng)Ģ■═ŲĖ„éĆśI(y©©)䚊ƥ─«aŲĘŻ¼ę“┤╦╬ęéāąĶ꬚{ė├╦∙ėąśI(y©©)䚊ƥ─«aŲĘĘ■äšĮė┐┌Ż¼Ą½ļSų°╬ęéā╔ŽŠĆĄ─ł÷Š░Ą─į÷╝ėŻ¼▀@śė¤oą╬Ą─į÷╝ė┴╦ī”śI(y©©)äšĘĮĮė┐┌Ą─š{ė├ē║┴”ĪŻČ°ŪęśI(y©©)䚊ƫaŲĘĮė┐┌Ę■äšų„ę¬æ¬ė├ė┌śI(y©©)䚥─ų„┴„│╠╗“ĻPµIą═æ¬ė├Ż¼▒╚▌^ųžŻ¼ŪęSLAĘ■䚥╚╝ēīė┤╬▓╗²RŻ¼┐╔─▄Ģ■ė░ĒæĄĮš¹éĆ═Ų╦]ŽĄĮy(t©»ng)Ą─Ēææ¬ĢrķgĪŻ
×ķ┴╦ĮŌøQ▀@ā╔éĆå¢Ņ}Ż¼╬ęéāįOėŗ┴╦Į³į┌ŠĆėŗ╦ŃüĒ▀MąąśI(y©©)䚥─«aŲĘą┼Žó«É▓ĮŠÅ┤µ▓▀┬įŻ¼Š▀¾wĄ─┴„│╠╚ńŽ┬ĪŻ
╬ęéāĢ■īó┤²═Ų╦]Ą─«aŲĘId╚½▓┐═©▀^Kafka«É▓ĮŽ┬░l(f©Ī)Ż¼į┌Stormųą╬ęéāĢ■ī”Ė„śI(y©©)äšĘĮĄ─«aŲĘ╩ūŽ╚▀MąąŠ█║ŽŻ¼▀_ĄĮ┼·╠Ä└ĒéĆöĄ(sh©┤)╗“š▀ĢrķggapĢrŻ¼į┘š{ė├Ė„śI(y©©)äšĘĮĄ─Įė┐┌Ż¼▀@śė£p╔┘ī”śI(y©©)äšĘĮĮė┐┌Ą─ē║┴”ĪŻ═©▀^š{ė├śI(y©©)äšĘĮĮė┐┌Ė³ą┬Ą─«aŲĘĀŅæB(t©żi)┼RĢrŠÅ┤µŲüĒ(Ė∙ō■(j©┤)Ė„śI(y©©)äš«aŲĘą┼ŽóĖ³ą┬ų▄Ų┌ĘųäeįOų├ŠÅ┤µ╩¦ą¦Ģrķg)Ż¼į┌ŠĆėŗ╦ŃĄ─Ģr║“ų▒ĮėŽ╚ūx╚Ī┼RĢrŠÅ┤µöĄ(sh©┤)ō■(j©┤)Ż¼ŠÅ┤µ▓╗┤µį┌Ą─ŪķørŽ┬Ż¼į┘ō¶┤®ĄĮśI(y©©)䚥─Įė┐┌Ę■äšĪŻ
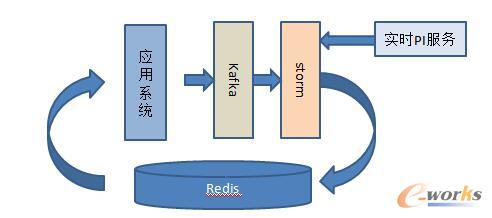
«aŲĘ«É▓ĮŠÅ┤µ┐“╝▄
4)į┌ŠĆėŗ╦Ń(2éĆĻPµIśI(y©©)äšīė╝▄śŗ─ŻēKĮķĮB)
ó┘śI(y©©)äšīė╝▄śŗ-öĄ(sh©┤)ō■(j©┤)ų╬└Ē║═įLå¢─ŻēKŻ¼ų¦│ųĄ─┤µā”Įķ┘|Ż¼─┐Ū░ų¦│ųĄ─┤µā”Įķ┘|ėąLocalcacheĪóRedisĪóHBaseĪóMySQL┐╔ęįų¦│ųÖMŽ“öUš╣ĪŻĮy(t©»ng)ę╗┼õų├Ż¼ī”═¼ę╗Ę▌öĄ(sh©┤)ō■(j©┤)Ż¼▓╔ė├Įy(t©»ng)ę╗┼õų├Ż¼┐╔ęįļSęŌ┤µā”į┌╚╬ęŌĮķ┘|Ż¼Ė∙ō■(j©┤)id▓ķįāĘĄ╗žĮy(t©»ng)ę╗Ė±╩ĮĄ─öĄ(sh©┤)ō■(j©┤)Ż¼ī”▓ķįāĮė┐┌═Ļ╚½═Ė├„ĪŻ
┤®═Ė▓▀┬į║═╚▌×─▓▀┬įŻ¼Redisų╗┤µā”┴╦¤ßöĄ(sh©┤)ō■(j©┤)Ż¼«öąĶę¬▓ķįā└õöĄ(sh©┤)ō■(j©┤)ät┐╔ęįūįäėĄĮŽ┬ę╗╝ē┤µā”╚ńHBase▓ķįāŻ¼▒▄├ŌŠÅ┤µ┘Yį┤└╦┘MĪŻ«öRedis│÷¼F(xi©żn)╣╩šŽĢr╗“šłŪ¾öĄ(sh©┤)«É│Ż╔ŽØqŻ¼│¼▀^š¹¾w│ą╩▄─▄┴”Ż¼┤╦ĢrĘ■äšĮĄ╝ēūįäė╔·ą¦Ż¼▓ó┐╔┼õų├╗»ĪŻ
![öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²](http://www.vmgcyvh.cn/upfile/eweb/2016827181037147.jpg)
ó┌śI(y©©)äšīė╝▄śŗ-═Ų╦]▓▀┬į─ŻēKŻ¼š¹éĆ┴„│╠╩ŪŽ╚īóė├æ¶ęŌłDĪóė├æ¶×gė[Ż¼ŽÓĻP═Ų╦]▓▀┬į╔·│╔Ą─«aŲĘ╝»║ŽĄ╚ū÷×ķöĄ(sh©┤)ō■(j©┤)▌ö╚ļŻ¼Įėų°░┤ššł÷Š░ęÄ(gu©®)ätŻ¼śI(y©©)äš▀ē▌ŗųžą┬▀^×VŻ¼Š█║ŽĪó┼┼ą“ĪŻūŅ║¾“×ūC║═Ų┤čbśI(y©©)䚊ƫaŲĘą┼Žó║¾▌ö│÷═Ų╦]ĮY╣¹Ż╗
╬ęéāī”┤╦┴„│╠├┐ę╗▓Į▀Mąą┴╦ę╗ą®─ŻēK╗»Ą─│ķŽ¾Ż¼īóųž┼┼ą“▀ē▌ŗ░┤▓Į¾E│ķŽ¾ĮŌ±ŅŻ¼│ķŽ¾╚ńėęłD╦∙╩ŠĄ─ČÓéĆĮM╝■Ż¼ķ_░l(f©Ī)ą┬Įė┐┌ĢrāHąĶę¬īóā╚▓┐DSLŲ┤čb▒Ń┐╔ęįĄ├ĄĮØMūŃśI(y©©)äšąĶŪ¾Ą─═Ų╦]Ę■䚯╗╠ßĖ▀┴╦┤·┤aĄ─Å═ė├┬╩║═┐╔ūxąįŻ¼£p╔┘┴╦│¼▀^50%Ą─ķ_░l(f©Ī)ĢrķgŻ╗ī”ė┌│õĘų“×ūCĄ──ŻēKĄ─Å═ė├Ż¼ėąą¦▒ŻūC┴╦Ę■䚥─┘|┴┐ĪŻ
![öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²](http://www.vmgcyvh.cn/upfile/eweb/2016827181037874.jpg)
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äšŅIė“ĪóąąśI(y©©)æ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻPūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://www.vmgcyvh.cn/
▒Š╬─ś╦Ņ}Ż║öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²
▒Š╬─ŠW(w©Żng)ųĘŻ║http://www.vmgcyvh.cn/html/news/10515519978.html



▀xą═ųąą─")
¾w“×ųąą─")
«aŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")


![www.vmgcyvh.cn═ž▓ĮERP|ERPŽĄĮy(t©»ng)|ERP▄ø╝■|ERP╣▄└ĒŽĄĮy(t©»ng)▄ø╝■|├Ō┘MERPŽĄĮy(t©»ng)|├Ō┘MERP▄ø╝■|├Ō┘M▀MõN┤µ▄ø╝■|├Ō┘Mé}Äņ╣▄└Ē▄ø╝■|├Ō┘MŽ┬▌dīŻśI(y©©)┘YėŹŠW(w©Żng)-öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²-═ž▓ĮERPŽĄĮy(t©»ng)▄ø╝■ŲĮ┼_11.5īŻśI(y©©)░µv10.1.2.1├Ō┘MŽ┬▌d](http://www.vmgcyvh.cn/upfile/eweb/2012624222611630_02.gif)

![www.vmgcyvh.cn═ž▓ĮERP|ERPŽĄĮy(t©»ng)|ERP▄ø╝■|ERP╣▄└ĒŽĄĮy(t©»ng)▄ø╝■|├Ō┘MERPŽĄĮy(t©»ng)|├Ō┘MERP▄ø╝■|├Ō┘M▀MõN┤µ▄ø╝■|├Ō┘Mé}Äņ╣▄└Ē▄ø╝■|├Ō┘MŽ┬▌dīŻśI(y©©)┘YėŹŠW(w©Żng)-öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²-═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_Äņ┤µ╣▄└ĒŽĄĮy(t©»ng)┼Óė¢ęĢŅlĮ╠▓─](http://www.vmgcyvh.cn/upfile/article/201272110454369977977_02.gif)

![www.vmgcyvh.cn═ž▓ĮERP|ERPŽĄĮy(t©»ng)|ERP▄ø╝■|ERP╣▄└ĒŽĄĮy(t©»ng)▄ø╝■|├Ō┘MERPŽĄĮy(t©»ng)|├Ō┘MERP▄ø╝■|├Ō┘M▀MõN┤µ▄ø╝■|├Ō┘Mé}Äņ╣▄└Ē▄ø╝■|├Ō┘MŽ┬▌dīŻśI(y©©)┘YėŹŠW(w©Żng)-öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²-═ž▓ĮERPžöäš╣▄└ĒŽĄĮy(t©»ng)ļŖūėłDĢ°](http://www.vmgcyvh.cn/images/ebook.gif)

![www.vmgcyvh.cn═ž▓ĮERP|ERPŽĄĮy(t©»ng)|ERP▄ø╝■|ERP╣▄└ĒŽĄĮy(t©»ng)▄ø╝■|├Ō┘MERPŽĄĮy(t©»ng)|├Ō┘MERP▄ø╝■|├Ō┘M▀MõN┤µ▄ø╝■|├Ō┘Mé}Äņ╣▄└Ē▄ø╝■|├Ō┘MŽ┬▌dīŻśI(y©©)┘YėŹŠW(w©Żng)-öy│╠┤¾öĄ(sh©┤)ō■(j©┤)īŹ█`Ż║Ė▀▓ó░l(f©Ī)æ¬ė├╝▄śŗ╝░═Ų╦]ŽĄĮy(t©»ng)░Ė└²-═ž▓ĮERPŽĄĮy(t©»ng)╣▄└Ē▄ø╝■ĮķĮB](http://www.vmgcyvh.cn/upfile/eweb/201241716929941_02.jpg)





