1.▒│Š░ĮķĮB
šäĄĮĘų▓╝╩ĮŽĄĮyŻ¼Š═▓╗Ą├▓╗╠ߥĮGoogleĄ─╚²±{±R▄ć:GFS,MapReduce║═BigTableĪŻļm╚╗Googleø]ėąķ_į┤▀@╚²éĆ╝╝ągĄ─īŹ¼Fį┤┤aŻ¼Ą½╩Ū╗∙ė┌▀@╚²Ų¬ķ_į┤╬─Ön, NutchĒŚ─┐ūėĒŚ─┐ų«ę╗Ą─Yahoo┘Yų·Ą─HadoopĘųäeīŹ¼F┴╦╚²éĆÅŖėą┴”Ą─ķ_į┤«aŲĘŻ║HDFSŻ¼MapReduce║═HBaseĪŻį┌┤¾öĄō■Ģr┤·Ą─▒│Š░Ž┬Ż¼įSČÓ╣½╦ŠČ╝ķ_╩╝▓╔ė├Hadoopū„×ķĄūīėĘų▓╝╩ĮŽĄĮyŻ¼Č°HadoopĄ─ķ_į┤╔ńģ^╚šęµ╗Ņ▄SŻ¼Hadoop╝ęūÕ▓╗öÓ░lš╣ēč┤¾Ż¼ęč│╔×ķITī├ūŅų╦╩ų┐╔¤ßĄ─«aŲĘĪŻ
▒Š╬─īóį┌║åå╬ĮķĮBHadoopų„ę¬│╔åTĄ─╗∙ĄA╔ŽŻ¼╠ĮėæHadoopį┌æ¬ė├ųąĄ─Ė─▀MĪŻ
Ą┌ę╗▓┐Ęų╩Ūī”HadoopšQ╔·║═¼FĀŅĄ─║åå╬├Ķ╩÷ĪŻ
Ą┌Č■▓┐Ęųīó║åå╬ĮķĮBhadoopĄ─ų„ę¬│╔åTŻ¼ų„ę¬░³└©╦¹éāĄ─╗∙▒Š╠žąį║═ā×ä▌ĪŻĘųäe╩ŪĘų▓╝╩Į╬─╝■ŽĄĮyHDFSŻ¼NoSQL╝ęūÕų«ę╗Ą─HBaseŻ¼Ęų▓╝╩Į▓󹹊Ä│╠ĘĮ╩ĮMapReduceęį╝░Ęų▓╝╩Įģfš{Ų„ZookeeperĪŻ
Ą┌╚²Īó╦─Īó╬Õ▓┐ĘųĘųäeĮķĮB┴╦HadoopĄ─▓╗═¼Ė─▀M║═╩╣ė├ĪŻ░┤┤╬ą“Ęųäe╩ŪfacebookĄ─īŹĢr╗»Ė─▀MŻ¼HadoopDBŻ¼ęį╝░CoHadoopĪŻ
ūŅ║¾╩Ū╬ęĄ─┐éĮY║═¾wĢ■ĪŻ
╚ń╣¹ī”HadoopĄ─╗∙▒Š╝▄śŗ║═╗∙ĄAų¬ūR╩ņŽżŻ¼┐╔ęįÅ─Ą┌╚²▓┐Ęų┐┤ŲĪŻ
2.ĻPė┌Hadoop
Hadoop▒Š╔ĒŲį┤ė┌Apache NutchĒŚ─┐Ż¼į°ę▓╩ŪLuceneĒŚ─┐Ą─ę╗▓┐ĘųĪŻÅ─ĮYśŗ╗»öĄō■Ż¼ĄĮ░ļĮYśŗ╗»öĄō■║═ĘŪĮYśŗ╗»öĄō■Ż¼Å─ĻPŽĄą═öĄō■ÄņĄĮĘŪĮYśŗ╗»öĄō■ÄņŻ©NoSQLŻ®Ż¼Ė³Ė▀ąį─▄Ą─▓óąąėŗ╦Ń/┼·╠Ä└Ē─▄┴”║═║Ż┴┐öĄō■┤µā”│╔×ķ¼F┤·ų„┴„IT╣½╦ŠĄ─ę╗ų┬ąĶŪ¾ĪŻ
2.1 HDFS
HDFSŻ¼╚½ĘQHadoop Distributed FilesystemŻ¼╩ŪHadoop╔·æB╚”Ą─Ęų▓╝╩Į╬─╝■ŽĄĮyĪŻĘų▓╝╩Į╬─╝■ŽĄĮy┐ńČÓ┼_ėŗ╦ŃÖC┤µā”╬─╝■Ż¼įōŽĄĮy╝▄śŗė┌ŠWĮjų«╔ŽŻ¼šQ╔·╝┤Š▀éõ┴╦ŠWĮjŠÄ│╠Ą─Å═ļsąįŻ¼▒╚Ųš═©┤┼▒P╬─╝■ŽĄĮyĖ³╝ėÅ═ļsĪŻ
2.1.1 HDFSöĄō■ēK
HDFSęį┴„╩ĮöĄō■įLå¢─Ż╩ĮüĒ┤µā”│¼┤¾╬─╝■Ż¼▀\ąąė┌╔╠ė├ė▓╝■╝»╚║╔ŽĪŻöĄō■╝»═©│Żė╔öĄō■į┤╔·│╔╗“Å─öĄō■į┤Å═ųŲČ°üĒŻ¼Įėų°ķLĢrķgį┌┤╦öĄō■╝»╔Ž▀MąąĖ±ŅÉĘų╬÷╠Ä└ĒĪŻ├┐┤╬Č╝īó╔µ╝░įōöĄō■╝»Ą─┤¾▓┐ĘųöĄō■╔§ų┴╚½▓┐Ż¼ę“┤╦ūx╚Īš¹éĆöĄō■╝»Ą─Ģrķgčė▀t▒╚ūx╚ĪĄ┌ę╗ŚlėøõøĢrķgĄ─čė▀tĖ³ųžę¬ĪŻČ°ę╗┤╬īæ╚ļĪóČÓ┤╬ūx╚Ī╩ŪūŅĖ▀ą¦Ą─įLå¢─Ż╩ĮĪŻėąę╗³c꬚f├„Ą─╩ŪŻ¼HDFS╩Ū×ķĖ▀öĄō■═╠═┬┴┐æ¬ė├ā×╗»Ą─Ż¼Č°▀@┐╔─▄Ģ■ęįĖ▀Ģrķgčė▀t×ķ┤·ārĪŻ
HDFS─¼šJĄ─ūŅ╗∙▒ŠĄ─┤µā”å╬į¬╩Ū64MĄ─öĄō■ēK(block)ĪŻHDFSĄ─ēK▒╚┤┼▒PēK(512ūų╣Ø)┤¾Ą├ČÓŻ¼─┐Ą─╩Ū×ķ┴╦ūŅąĪ╗»īżųĘķ_õNĪŻHDFS╔ŽĄ─╬─╝■ę▓▒╗äØĘų×ķČÓéĆĘųēK(chunk)Ż¼ū„×ķ¬Ü┴ó┤µā”å╬į¬ĪŻ┼cŲõ╦¹╬─╝■ŽĄĮy▓╗═¼Ą─╩ŪŻ¼HDFSųąąĪė┌ę╗éĆēK┤¾ąĪĄ─╬─╝■▓╗Ģ■š╝ō■š¹éĆēKĄ─┐šķgĪŻ
ēK│ķŽ¾ĮoĘų▓╝╩Į╬─╝■ŽĄĮyĦüĒĄ─║├╠ÄŻ║
╬─╝■Ą─┤¾ąĪ┐╔ęį┤¾ė┌ŠWĮjųą╚╬ęŌę╗éĆ┤┼▒PĄ─╚▌┴┐ĪŻ
╩╣ė├ēK│ķŽ¾Č°ĘŪš¹éĆ╬─╝■ū„×ķ┤µā”å╬į¬Ż¼┤¾┤¾║å╗»┴╦┤µā”ūėŽĄĮyĄ─įOėŗŻ¼═¼Ģrę▓Ž¹│²┴╦ī”į¬öĄō■Ą─ŅÖæ]ĪŻ
ēKĘŪ│Ż▀m║Žė├ė┌öĄō■éõĘ▌▀MČ°╠ß╣®öĄō■╚▌Õe─▄┴”║═┐╔ė├ąįĪŻ
2.1.2 Namenode║═Datanode
namenode║═datanodeĄ─╣▄└Ēš▀-╣żū„š▀─Ż╩Įėą³cŅÉ╦Ųų„Å─╝▄śŗĪŻnamenodeī”æ¬ČÓéĆdatanodeĪŻnamenode╣▄└Ē╬─╝■ŽĄĮyĄ─├³├¹┐šķgŻ¼ŠSūo╬─╝■ŽĄĮy║═ā╚▓┐Ą─╬─╝■╝░─┐õøĪŻdatanode╩Ū╬─╝■ŽĄĮyĄ─šµš²╣żū„╣سcŻ¼Ė∙ō■ąĶę¬┤µā”▓óÖz╦„öĄō■ēKŻ©ę╗░Ń╩▄namenodeš{Č╚Ż®Ż¼▓óŪęČ©Ų┌Ž“namenode░l╦═╦³éā╦∙┤µā”Ą─ēKĄ─┴ą▒ĒĪŻ
namenodeę╗Ą®ÆņĄ¶Ż¼╬─╝■ŽĄĮyĄ─╦∙ėą╬─╝■Š═üG╩¦┴╦Ż¼▓╗ų¬Ą└╚ń║╬Ė∙ō■datanodeĄ─ēKüĒųžĮ©╬─╝■ĪŻę“┤╦Ż¼namenodeĄ─╚▌Õe╗“š▀éõĘ▌╩Ū║▄ųžę¬Ą─ĪŻį┌HDFSųą┤µį┌secondarynamenodeŻ©ļm╚╗▓╗═Ļ╚½╩ŪéĆnamenodeĄ─éõĘ▌Ż¼Ė³┤_ŪąĄ─╩ŪéĆ▌oų·╣سcŻ®ų▄Ų┌ąįīóį¬öĄō■╣سcĄ─├³├¹┐ž╝■ńRŽ±╬─╝■║═ą▐Ė─╚šųŠ║Ž▓óĪŻ
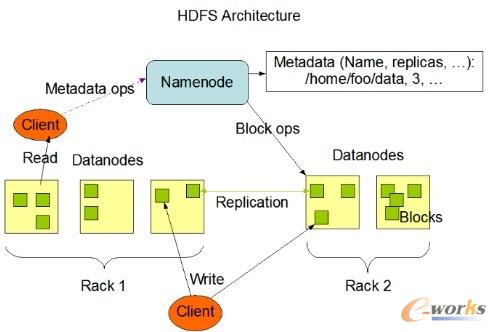
łD1 namenode║═datanodeĄ─╣▄└Ēš▀-╣żū„š▀─Ż╩Į
2.2 HBase
Ė·é„ĮyĄ─ĻPŽĄą═öĄō■ÄņŻ©RDBMSŻ®╗∙ė┌ąą┤µā”▓╗═¼Ż¼HBase╩Ūę╗éĆĘų▓╝╩ĮĄ─Ż¼į┌HDFS╔Žķ_░lĄ─├µŽ“┴ąĄ─Ęų▓╝╩ĮöĄō■ÄņĪŻHBaseąąųąĄ─┴ąĘų│╔“┴ąūÕ”Ż©column familyŻ®Ż¼╦∙ėąĄ─┴ąūÕ│╔åTėąŽÓ═¼Ą─Ū░ŠYĪŻ╦∙ėą┴ąūÕ│╔åTČ╝ę╗Ų┤µĘ┼į┌╬─╝■ŽĄĮyųąĪŻ
2.2.1 ┼cRDBMS▒╚▌^
HBase═©▀^į┌HDFS╔Ž╠ß╣®ļSÖCūxīæüĒĮŌøQHadoop▓╗─▄╠Ä└ĒĄ─å¢Ņ}ĪŻHBaseūįĄūīėįOėŗķ_╩╝╝┤Š█Į╣ė┌Ė„ĘN┐╔╔ņ┐sąįå¢Ņ}Ż║▒Ē┐╔ęį║▄“Ė▀”Ż¼ėąöĄ╩«ā|éĆöĄō■ąąŻ╗ę▓┐╔ęį║▄“īÆ”Ż¼ėąöĄ░┘╚féĆ┴ąŻ╗╦«ŲĮĘųģ^▓óį┌╔ŽŪ¦éĆŲš═©╔╠ė├ÖC╣سc╔ŽūįäėÅ═ųŲĪŻ▒ĒĄ──Ż╩Į╩Ū╬’└Ē┤µā”Ą─ų▒ĮėĘ┤ė│Ż¼╩╣ŽĄĮyėą┐╔─▄╠ßĖ▀Ė▀ą¦Ą─öĄō■ĮYśŗĄ─ą“┴ą╗»Īó┤µā”║═Öz╦„ĪŻ
Č°RDBMS╩Ū─Ż╩Į╣╠Č©Īó├µŽ“ąąĄ─öĄō■ÄņŪęŠ▀ėąACIDąį┘|║═Å═ļsĄ─SQL▓ķįā╠Ä└Ēę²ŪµŻ¼ÅŖš{╩┬╬’Ą─ÅŖę╗ų┬ąįŻ©strong consistencyŻ®Īóģóšš═Ļš¹ąįŻ©referential integrityŻ®ĪóöĄō■│ķŽ¾┼c╬’└Ē┤µā”īėŽÓī”¬Ü┴óŻ¼ęį╝░╗∙ė┌SQLšZčįĄ─Å═ļs▓ķįāų¦│ųĪŻ
2.2.2 HBase╠žąį
║åå╬┴ą┼eŽ┬HBaseĄ─ĻPµI╠žąįĪŻ
ø]ėąšµš²Ą─╦„ę²Ż║ąą╩ŪĒśą“┤µā”Ą─Ż¼├┐ąąųąĄ─┴ąę▓╩ŪŻ¼╦∙ęį▓╗┤µį┌╦„ę²┼“├øĄ─å¢Ņ}Ż¼Č°Ūę▓Õ╚ļąį─▄║═▒ĒĄ─┤¾ąĪėąĻPĪŻ
ūįäėĘųģ^Ż║į┌▒Ēį÷ķLĄ─Ģr║“Ż¼▒ĒĢ■ūįäėĘų┴č│╔ģ^ė“Ż©regionŻ®Ż¼▓óĘų▓╝ĄĮ┐╔ė├Ą─╣سc╔ŽĪŻ
ŠĆąįöUš╣Ż║ī”ė┌ą┬į÷╝ėĄ─╣سcŻ¼ģ^ė“ūįäėųžą┬▀MąąŲĮ║ŌŻ¼žō▌dĢ■Š∙ä“Ęų▓╝ĪŻ
╚▌ÕeŻ║┤¾┴┐Ą─╣سcęŌ╬Čų°├┐éĆ╣سcųžę¬ąį▓ó▓╗═╗│÷Ż¼╦∙ęį▓╗ė├ō·ą─╣سc╩¦ą¦å¢Ņ}ĪŻ
┼·╠Ä└ĒŻ║┼cMapReduceĄ─╝»│╔┐╔ęį╚½▓󹹥ž▀MąąĘų▓╝╩Įū„śIĪŻ
2.3 MapReduce
MapReduce╩Ūę╗ĘN┐╔ė├ė┌öĄō■╠Ä└ĒĄ─ŠÄ│╠─Żą═Ż¼╩Ūę╗éĆ║åå╬ęūė├Ą─▄ø╝■┐“╝▄Ż¼╗∙ė┌╦³īæ│÷üĒĄ─æ¬ė├│╠ą“─▄ē“▀\ąąį┌ė╔╔ŽŪ¦éĆ╔╠ė├ÖCŲ„ĮM│╔Ą─┤¾ą═╝»╚║╔ŽŻ¼▓óęįę╗ĘN┐╔┐┐╚▌ÕeĄ─ĘĮ╩Į▓óąą╠Ä└Ē╔ŽT╝ēäeĄ─öĄō■╝»ĪŻ
2.3.1 Map & Reduce
ę╗éĆMap/Reduce ū„śIŻ©jobŻ®═©│ŻĢ■░č▌ö╚ļĄ─öĄō■╝»ŪąĘų×ķ╚¶Ė╔¬Ü┴óĄ─öĄō■ēKŻ¼ė╔ map╚╬äšęį═Ļ╚½▓󹹥─ĘĮ╩Į╠Ä└Ē╦³éāĪŻ┐“╝▄Ģ■ī”mapĄ─▌ö│÷Ž╚▀Mąą┼┼ą“Ż¼╚╗║¾░čĮY╣¹▌ö╚ļĮoreduce╚╬äšĪŻ═©│Żū„śIĄ─▌ö╚ļ║═▌ö│÷Č╝Ģ■▒╗┤µā”į┌╬─╝■ŽĄĮyŻ©ę╗░Ń×ķHDFSŻ®ųąĪŻš¹éĆ┐“╝▄žōž¤╚╬䚥─š{Č╚║═▒O┐žŻ©jobtrackerģfš{ū„śIĄ─▀\ū„Ż¼tasktracker▀\ąąū„śIäØĘų║¾Ą─╚╬䚯®Ż¼ęį╝░ųžą┬ł╠ąąęčĮø╩¦öĪĄ─╚╬äšĪŻ
═©│ŻŻ¼Map/Reduce┐“╝▄║═Ęų▓╝╩Į╬─╝■ŽĄĮy╩Ū▀\ąąį┌ę╗ĮMŽÓ═¼Ą─╣سc╔ŽĄ─Ż¼ę▓Š═╩ŪšfŻ¼ėŗ╦Ń╣سc║═┤µā”╣سc═©│Żį┌ę╗ŲĪŻ▀@ĘN┼õų├į╩įS┐“╝▄į┌─Ūą®ęčĮø┤µ║├öĄō■Ą─╣سc╔ŽĖ▀ą¦Ąžš{Č╚╚╬䚯¼▀@┐╔ęį╩╣š¹éĆ╝»╚║Ą─ŠWĮjĦīÆ▒╗ĘŪ│ŻĖ▀ą¦Ąž└¹ė├ĪŻ
2.3.2 Matser/Slave╝▄śŗ
Map/Reduce┐“╝▄ė╔ę╗éĆå╬¬ÜĄ─master JobTracker ║═├┐éĆ╝»╚║╣سcę╗éĆslave TaskTracker╣▓═¼ĮM│╔ĪŻmasteržōž¤š{Č╚śŗ│╔ę╗éĆū„śIĄ─╦∙ėą╚╬䚯¼▀@ą®╚╬äšĘų▓╝į┌▓╗═¼Ą─slave╔ŽŻ¼master▒O┐ž╦³éāĄ─ł╠ąąŻ¼ųžą┬ł╠ąąęčĮø╩¦öĪĄ─╚╬äšĪŻČ°slaveāHžōž¤ł╠ąąė╔masterųĖ┼╔Ą─╚╬äšĪŻ
æ¬ė├│╠ą“ų┴╔┘æ¬įōųĖ├„▌ö╚ļ/▌ö│÷Ą─╬╗ų├Ż©┬ĘÅĮŻ®Ż¼▓ó═©▀^īŹ¼F║Ž▀mĄ─Įė┐┌╗“│ķŽ¾ŅÉ╠ß╣®map║═reduce║»öĄĪŻį┘╝ė╔ŽŲõ╦¹ū„śIĄ─ģóöĄŻ¼Š═śŗ│╔┴╦ū„śI┼õų├Ż©jobconfigurationŻ®ĪŻ╚╗║¾Ż¼HadoopĄ─ job client╠ßĮ╗ū„śIŻ©jar░³/┐╔ł╠ąą│╠ą“Ą╚Ż®║═┼õų├ą┼ŽóĮoJobTrackerŻ¼║¾š▀žōž¤Ęų░l▀@ą®▄ø╝■║═┼õų├ą┼ŽóĮoslaveĪóš{Č╚╚╬äš▓ó▒O┐ž╦³éāĄ─ł╠ąąŻ¼═¼Ģr╠ß╣®ĀŅæB║═į\öÓą┼ŽóĮojob-clientĪŻ
2.4 Zookeeper
Zookeeper╩Ūę╗éĆĖ▀┐╔ė├Ą─Ęų▓╝╩ĮöĄō■╣▄└Ē┼cŽĄĮyģfš{┐“╝▄ĪŻ║åå╬Ą─šfŻ¼Š═╩ŪéĆĘų▓╝╩Įģfš{Ų„ĪŻ╦³ęįų„Å─Ą─╝▄śŗŻ¼╗∙ė┌Paxos╦ŃĘ©īŹ¼FŻ¼▒ŻūC┴╦Ęų▓╝╩ĮŁhŠ│ųąöĄō■Ą─ÅŖę╗ų┬ąįŻ¼ę▓ę“┤╦Ė„ĘNĘų▓╝╩Įķ_į┤ĒŚ─┐ųąČ╝ėą╦³Ą─╔Ēė░ĪŻ
2.4.1 ZookeeperÖCųŲ
ZookeeperĄ─║╦ą─╩Ūę╗éĆŠ½║åĄ─╬─╝■ŽĄĮyŻ¼╦³Ą─įŁšZ▓┘ū„╩Ūę╗ĮMžSĖ╗Ą─śŗ╝■Ż©building blockŻ®Ż¼┐╔ė├ė┌īŹ¼F║▄ČÓģfš{öĄō■ĮYśŗ║═ģfūhŻ¼░³└©Ęų▓╝╩ĮĻĀ┴ąĪóĘų▓╝╩Įµi║═ę╗ĮM═¼╝ē╣سcųąĄ─“ŅIī¦š▀▀x┼e”Ż©leader electionŻ®ĪŻ
ZookeeperīŹ¼FĄ─╩ŪPaxos╦ŃĘ©ĪŻZookeeper╝»╚║åóäė║¾ūįäė▀Mąąleader selectionŻ¼═ČŲ▒▀x│÷ę╗┼_ÖCŲ„ū„×ķLeaderŻ¼Ųõ╦¹Ą─Č╝╩ŪFollowerĪŻ═©▀^heartbeatĄ─ÖCųŲŻ¼FollowerÅ─Leader½@╚Ī├³┴Ņ╗“š▀Ž¹ŽóŻ¼═¼▓Įūį╝║Ą─öĄō■Ż¼║═Leader▒Ż│ųę╗ų┬ĪŻ×ķ┴╦▒ŻūCöĄō■Ą─ę╗ų┬ąįŻ¼ų╗ėą«ö░ļöĄęį╔ŽĄ─FollowerĄ─ĀŅæB║═Leader│╔╣”═¼▓Į┴╦ų«║¾Ż¼▓┼šJ×ķ▀@┤╬öĄō■Ė³ą┬╩Ū│╔╣”Ą─ĪŻ×ķ┴╦▀x┼eĘĮ▒ŃŻ¼Zookeeper╝»╚║öĄ─┐╩ŪŲµöĄĪŻ
3.Hadoopį┌FacebookūāĄ├īŹĢr
šō╬─ų„ę¬ĮŌßī┴╦Facebookę²▀MHadoopĄ─įŁę“ĪŻĮY║Žūį╝║Ą─ąĶŪ¾Ż¼Facebookī”hadoop▀Mąą┴╦Ė³īŹĢrĄ─Ė─▀MĪŻ
3.1 HDFS┼cMySQLĄ─ąį─▄╗źča
HDFS▀m║Ž┤¾ēKĄžūx╚ĪöĄō■Ż©═Ų╦]╣سc╩Ū64MŻ®Ż¼╦³ĻPė┌ļSÖCūx╚ĪĄ─╣żū„Ą─accesslatency▒╚▌^┤¾Ż¼╦∙ęįę╗░ŃĢ■ė├┤¾ęÄ─ŻĄ─MySQL╝»╚║ĮY║Žmemcached▀@śėĄ─ŠÅ┤µ╣żŠ▀üĒū÷╠Ä└ĒĪŻį┌FacebookųąŻ¼Å─Hadoopųą«a╔·Ą─ŅÉ╦ŲųąķgĮY╣¹Ą─öĄō■Ģ■čb▌dĄĮMySQL╝»╚║╗“š▀memcachedųą╚źŻ¼ė├üĒ▒╗webīė╩╣ė├ĪŻ
═¼ĢrŻ¼HDFSĄ─Ēśą“ūx╚Īąį─▄║▄║├ĪŻFacebookąĶŪ¾īæĘĮ├µĄ─Ė▀═╠═┬┴┐Ż¼┤·ārĄ═Ą─ÅŚąį┤µā”Ż¼═¼Ģrę¬Ū¾Ą═čė▀t║═ė▓▒P╔ŽĖ▀ą¦Ą─Ēśą“║═ļSÖCūx╚ĪĪŻMySQL┤µā”ę²Ūµ▒╗ūC├„ėą▒╚▌^Ė▀Ą─ļSÖCūx╚Ī─▄┴”Ż¼Ą½╩ŪļSÖCīæ═╠═┬┬╩▒╚▌^▓ŅĪŻę“┤╦Ż¼FacebookøQČ©▓╔ė├Hadoop║═HBaseüĒŲĮ║ŌĒśą“║═ļSÖCūx╚ĪĄ─ąį─▄Ż¼Č°▓╗╩Ūų╗▓╔ė├MySQL╝»╚║üĒ▓╗öÓćLįćę╗ĘNļyęį░č╬šĄ─balanceĪŻŠ▀¾wFacebookĄ─ąĶŪ¾īóį┌Ž┬ę╗╣Øūą╝ÜŲ╩╬÷ĪŻ
3.2 FacebookąĶŪ¾
FacebookšJ×ķŻ¼ė├╦¹éāęčėąĄ─╗∙ė┌MySQL╝»╚║Ą─ę╗ą®ĮŌøQĘĮ░ĖüĒ╠Ä└Ēå¢Ņ}ęčĮøė÷ĄĮ┴╦Ų┐ŅiĪŻų«Ū░Ą─ė├└²ī”╣żū„┴┐Ą─öUš╣╩Ūėą╠¶æąįĄ─ĪŻį┌ę╗éĆRDBMSĄ─ŁhŠ│Ž┬ĮŌøQĘŪ│ŻĖ▀Ą─īæ═╠═┬┴┐Ż¼┤¾öĄō■Ż¼▓╗┐╔ŅA£yį÷ķL╝░Ųõ╦¹å¢Ņ}ūāĄ├╩«Ęų└¦ļyĪŻ
3.3 ▀xō±Hadoop║═HBaseįŁę“
▓╔ė├Hadoop║═HBaseüĒĮŌøQęį╔ŽąĶŪ¾Ą─┤µā”ŽĄĮyĘĮ░ĖĄ─įŁę“┐╔ęį┐éĮY×ķęįŽ┬Äū³cŻ║
ÅŚąįŻ║ąĶę¬─▄ē“ė├ūŅąĪĄ─ķ_õN║═┴ŃÕ┤ÖCą▐Å═ĢrķgüĒī”┤µā”ŽĄĮyį÷┴┐╩ĮĄžöU╚▌ĪŻ▀@└’Ą─öU╚▌æ¬įōųĖĄ─╩Ū┐╔ęį▒╚▌^ĘĮ▒ŃĄžīŹĢrį÷╝ėĘ■äšŲ„┼_öĄüĒæ¬ī”ę╗ą®Ė▀ĘÕ╗“š▀═╗░lĘ■äšąĶŪ¾ĪŻ
Ė▀Ą─īæ═╠═┬┴┐
Ė▀ą¦Ą─ė▓▒PļSÖCūxīæ
Ė▀┐╔ė├ąį║═╚▌×─
Õeš`Ė¶ļxŻ║«öŠų▓┐öĄō■ÄņÆņĄ¶╗“š▀Ę■äšŲ„▓╗─▄╠ß╣®Ę■䚥─Ģr║“Ż¼ūīūŅ╔┘Ą─ė├æ¶╩▄ĄĮė░ĒæĪŻHDFSæ¬ī”▀@śėĄ─ł÷Š░▀Ć╩Ū║▄▓╗ÕeĄ─ĪŻ
ūxīæĖ─Ą─įŁūėąįŻ║Ąūīė┤µā”ŽĄĮyßśī”Ė▀▓ó░l┴┐Ą─ąĶŪ¾
ĘČć·Æ▀├ĶŻ║ųĖ╠žČ©ł÷Š░Ž┬Ė▀ą¦½@╚Īę╗éĆĘČć·ĮY╣¹╝»ĪŻ
HBaseęčĮøęįkey-value┤µā”Ą─ĘĮ╩Į╠ß╣®┴╦Ė▀ę╗ų┬ąįĄ─Ė▀īæ═╠═┬Ż¼Ūęį┌┤¾ęÄ─ŻöĄō■é„╦═║═┐ņ╦┘ļSÖCīæęį╝░┴„╩ĮūxĘĮ├µ▒Ē¼Fā׫ÉĪŻ╦³═¼Ģr▒ŻūC┴╦ąąīė┤╬Ą─įŁūėąįĪŻÅ─öĄō■─Żą═Ą─ĮŪČ╚┐┤Ż¼├µŽ“┴ąĄ─īŹ¼FĮoöĄō■┤µā”ĦüĒ┴╦śOĖ▀Ą─ņ`╗ŅąįŻ¼“īÆ”ąąį╩įSį┌ę╗éĆtableā╚┤µĘ┼░┘╚föĄ┴┐╝ēĄ─▒╗╦„ę²Ą─ųĄĪŻ
ļm╚╗HDFSĄ─║╦ą─namenodeĄ─Õ┤ÖCĢ■ĦüĒŠ▐┤¾ė░ĒæŻ¼Ą½╩ŪFacebookėąą┼ą─┤“įņę╗éĆį┌║Ž└ĒĢrŽ▐ā╚Ą─Ė▀┐╔ė├Ą─NameNodeĪŻĖ∙ō■ę╗ą®īŹ█`£yįćŻ¼Facebookī”HDFS▀Mąą┴╦įOėŗ║═Ė─▀MŻ¼ų„ę¬ßśī”namenodeĪŻīóį┌Ž┬╣Øš╣ķ_ĪŻ
3.4 īŹĢrHDFS
HDFSäéķ_╩╝╩Ū×ķ┴╦ų¦│ųMapReduce▀@śėĄ─▓óąąæ¬ė├Ą─öĄō■┤µ╚ĪĄ─Ż¼╩Ū├µŽ“┼·╠Ä└ĒŽĄĮyĄ─Ż¼╦∙ęįį┌īŹĢrĘĮ├µųv▒Š╔Ē┐╔─▄╩Ū┤µį┌▓╗ūŃĄ─ĪŻFacebookų„ę¬Ė─įņį┌ė┌ę╗éĆĖ▀┐╔ė├Ą─AvatarNodeĪŻ
╬ęéāų¬Ą└HDFSĄ─namenodeę╗Ą®ÆņĄ¶Ż¼š¹éĆ╝»╚║Š═Ą├Ą╚ĄĮnamenodeį┘┤╬åóäė▓┼─▄└^└m▀\ąą╠ß╣®Ę■䚯¼╦∙ęįąĶę¬▀@éƤßéõĘ▌——AvatarNodeĄ─įOėŗĪŻį┌HDFSåóäėĄ─Ģr║“Ż¼namenode╩ŪÅ─ę╗éĆĮąfsimageĄ─╬─╝■└’ūx╚Ī╬─╝■ŽĄĮyĄ─į¬öĄō■Ą─ĪŻį¬öĄō■ą┼Žó░³└©┴╦HDFS╔Ž╦∙ėą╬─╝■║═─┐õøĄ─├¹ūų║═į¬öĄō■ĪŻĄ½╩Ūnamenode▓╗Ģ■│ų└mĄž╚ź┤µ├┐ę╗ēKblockĄ─╬╗ų├ą┼ŽóĪŻ╦∙ęį└õåóäėnamenodeĄ─Ģr║“░³└©ā╔▓┐ĘųŻ║╩ūŽ╚ūx╬─╝■ŽĄĮyńRŽ±Ż╗╚╗║¾Ż¼┤¾▓┐ĘųdatanodeģRł¾▀M│╠╔ŽĄ─blocką┼ŽóŻ¼ęį┤╦üĒ╗ųÅ═╝»╚║╔Ž├┐ę╗ēKęčų¬blockĄ─╬╗ų├ą┼ŽóĪŻ▀@śėĄ─└õåóäėĢ■╗©║▄ķLĢrķgĪŻ
ļm╚╗ę╗éĆéõė├Ą─┐╔ė├node┐╔ęį▒▄├ŌfailoverĢr║“╚źūx┤┼▒P╔ŽĄ─fsimageŻ¼Ą½╩Ūę└╚╗ąĶę¬Å─datanodes└’½@╚Īblocką┼ŽóĪŻ╦∙ęįŻ¼ĢrķgŽÓī”▀Ć╩ŪŲ½ķLĪŻė┌╩ŪšQ╔·┴╦AvatarNodeĪŻ
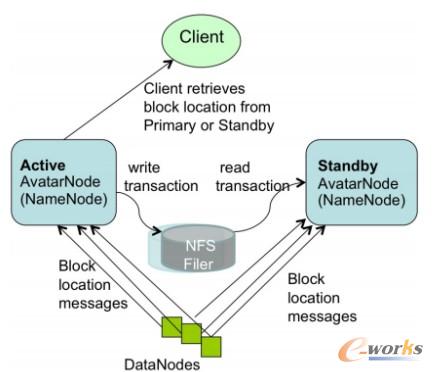
łD2 īŹĢrHDFS
╚ńłD╦∙╩ŠĪŻHDFSōĒėąā╔éĆAvatarNode——Active AvatarNode║═Standby AvatarNodeĪŻ╦¹éāą╬│╔┴╦ę╗ī”“ų„▒╗äė¤ßéõĘ▌”Ż©active-passive-hot-standbyŻ®ĪŻAvatarNode╩Ūī”NameNodeĄ─░³čbĪŻFacebookĄ─HDFS╝»╚║Č╝▓╔ė├NFSüĒ┤µę╗Ę▌╬─╝■ŽĄĮyńRŽ±Ą─éõĘ▌║═ę╗Ę▌╩┬╬’╚šųŠĄ─éõĘ▌ĪŻActive AvatarNode░čūį╝║╠Ä└ĒĄ─╩┬äšīæ▀MNFS└’Ą─╩┬äš╚šųŠĪŻ═¼ĢrŻ¼StandbyAvatarNode┤“ķ_NFS╔Ž═¼ę╗Ę▌╩┬äš╚šųŠŻ¼╚╗║¾į┌ūį╝║Ą─├³├¹┐šķgā╚ķ_╩╝ł╠ąą╩┬䚯¼ęį▒ŻūCūį╝║Ą─├³├¹┐šķg▒M┐╔─▄║═│§╩╝ą┼ŽóĮėĮ³ĪŻStandby AvatarNode═¼ĢrššŅÖĄĮ│§╩╝ą┼ŽóĄ─║╦▓ķ▓óäōĮ©ą┬Ą─╬─╝■ŽĄĮyńRŽ±Ż¼║═HDFSŽÓ▒╚Š═ø]ėą┴╦ĘųļxĄ─SecondNameNodeĪŻ
Datanodes═¼Ģr║═ā╔éĆAvatarNodeĮ╗┴„ĪŻ▀@▒ŻūC┴╦Standby╠Äę▓½@Ą├ĄĮūŅą┬Ą─blockĀŅæBą┼ŽóŻ¼ęįį┌ĘųńŖĢrķg╝ēā╚▐D╗»│╔×ķActiverĄ─NodeŻ©ų«Ū░šfnamenodeĄ─└õåóäėĄ─ĢrķLå¢Ņ}┐╔ęįĮŌøQ┴╦Ż®ĪŻAvatar DataNodeŽÓ╗źų«ķg▌ö╦═ą─╠°Ż¼blocką┼ŽóģRł¾║═Įė╩▄ĄĮĄ─blockĪŻAvatar DataNodes╝»│╔┴╦ZookeeperŻ¼ę“┤╦╦¹éāų¬Ą└ų„╣سcą┼ŽóŻ¼Ģ■ł╠ąąų„╣سc░l╦═Ą─Å═ųŲ/äh│²├³┴ŅŻ©╗∙ė┌ZookeeperĄ─leader selection║═heartbeatÖCųŲŻ®Ż¼Č°üĒūįStandby AvatarNodeĄ─Å═ųŲ/äh│²šłŪ¾╩Ū║÷┬įĄ─ĪŻ
ī”ė┌╩┬äš╚šųŠĄ─ėøõøŻ¼▀Ć▀Mąą┴╦ę╗ą®Ė─▀MĪŻ
Ż©1Ż®×ķ┴╦ūī╣╩šŽ║═╩¦ą¦▒M┐╔─▄═Ė├„Ż¼Standby▒žĒÜų¬Ą└╩¦ą¦░l╔·ĢrĄ─block╬╗ų├ą┼ŽóŻ¼╦∙ęįī”├┐ę╗ēKblockĘų┼õėøõøę╗éĆŅ~═ŌĄ─ėøõø╚šųŠĪŻ▀@śėį╩įS┐═æ¶Č╦į┌░l╔·╩¦ą¦Ą─Ģr┐╠Ū░▀Ć╩Ūę╗ų▒į┌īæ╬─╝■ĪŻ
Ż©2Ż®«öStandbyŽ“š²į┌▒╗Activeīæ╩┬äšėøõøĄ─╚šųŠ└’ūx╚Ī╩┬äšą┼ŽóĄ─Ģr║“Ż¼ėą┐╔─▄ūxĄĮĄ─╩Ūę╗éĆŠų▓┐Ą─╩┬äšĪŻ×ķ┴╦▒▄├Ō▀@śėĄ─å¢Ņ}Ż¼Įo├┐éĆę¬īæ▀M╚šųŠ└’Ą─╩┬äšį÷╝ėėøõø╩┬äšķLČ╚ą┼ŽóŻ¼╩┬äšid║═ąŻ“×║═ĪŻ
ę¬┴╦ĮŌĖ³Š▀¾wĄ─ą┼ŽóŻ¼┐╔ęįÅ─įŁpaperųą½@Ą├Ė³ČÓŠ▀¾wĄ─ŪķørĪŻ
4.HadoopDB
HadoopDB║åå╬ĮķĮBŽ┬įOėŗ└Ē─Ņ║═╦¹Ą─╝▄śŗĪŻ
4.1 HadoopDB└Ē─Ņ
HadoopDB╩Ūę╗éĆ╗ņ║ŽŽĄĮyĪŻ╗∙▒Š╦╝Žļ╩Ūė├MapReduceū„×ķ┼cš²į┌▀\ąąų°å╬╣سcDBMSīŹ└²Ą─ČÓśė╗»╣سcĄ─═©ą┼īėĪŻ▓ķįāšZčįė├SQL▒Ē╩ŠŻ¼▓óė├¼Fėą╣żŠ▀ĘŁūg│╔MapReduce┐╔ęįĮė╩▄Ą─šZčįŻ¼╩╣Ą├▒M┐╔─▄ČÓĄ─╚╬äš┐╔ęį▒╗═Ų╦═ĄĮ├┐éĆĖ▀ąį─▄Ą─å╬╣سcöĄō■Äņ╔ŽĪŻ▀@śė╗∙ė┌MapReduceĄ─▓óąą╗»Ą─öĄō■Äņ┤·ārÄū║§╩Ū┴ŃĪŻę“×ķMapReduce╩Ū¼FėąĄ─ĪŻ
HadoopDB▒│║¾Ą─ę╗ą®ų„ę¬╦╝Žļ░³└©ęįŽ┬ā╔éĆĻPµIūųŻ║share-nothing MPP╝▄śŗ║═parallel databasesĪŻ
4.2 HadoopDB╝▄śŗĮķĮB
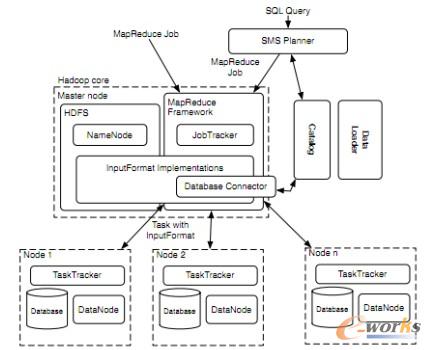
łD3 HadoopDB╝▄śŗ
ū„×ķę╗éĆ╗ņ║ŽĄ─ŽĄĮyŻ¼ūī╬ęéā┐┤┐┤HadoopDBė╔──ą®▓┐Ęųśŗ│╔Ż║HDFSŻ¼MapReduceŻ¼SMS PlannerŻ¼DB ConnectorĄ╚Ą╚ĪŻHadoopDBĄ─║╦ą─┐“╝▄▀Ć╩ŪHadoopŻ¼Š▀¾wŠ═╩Ū┤µā”īėHDFSŻ¼║═╠Ä└ĒīėMapReduceĪŻĻPė┌HDFS╔ŽnamenodeŻ¼datanodeĖ„ūį╠Ä└Ē╚╬䚯¼öĄō■éõĘ▌┤µā”ÖCųŲęį╝░MapReduceā╚master-slave╝▄śŗŻ¼jobtracker║═tasktrackerĖ„ūįĄ─╣żū„ÖCųŲ║═╚╬äšžō▌dĘų┼õŻ¼öĄō■▒ŠĄž╗»╠žąįĄ╚ā╚╚▌Š═▓╗įö╝Üšf┴╦ĪŻŽ┬├µī”ų„꬜ŗ│╔▓┐╝■ū÷║åå╬ĮķĮBŻ║
1.Databae ConnectorŻ║│ąō·Ą─╩Ūnode╔Ž¬Ü┴óöĄō■ÄņŽĄĮy║═TaskTrackerų«ķgĄ─Įė┐┌ĪŻłDųą┐╔ęį┐┤ĄĮ├┐éĆsingleĄ─öĄō■ÄņČ╝ĻP┬ōę╗éĆdatanode║═ę╗éĆtasktrackerĪŻ╦¹é„▌öSQLšZŠõŻ¼Ą├ĄĮę╗ą®KVĘĄ╗žųĄĪŻöUš╣┴╦HadoopĄ─InputFormatŻ¼╩╣Ą├┼cMapReduce┐“╝▄īŹ¼F¤o┐pŲ┤ĮėĪŻ
2.CatalogŻ║ŠS│ųöĄō■ÄņĄ─į¬öĄō■ą┼ŽóĪŻ░³└©ā╔▓┐ĘųŻ║öĄō■ÄņĄ─▀BĮėģóöĄ║═į¬öĄō■Ż¼╚ń╝»╚║ųąĄ─öĄō■╝»Ż¼Å═▒Š╬╗ų├Ż¼öĄō■Ęųģ^ī┘ąįĪŻ¼Fį┌╩ŪęįXMLüĒėøõø▀@ą®į¬öĄō■ą┼ŽóĄ─ĪŻė╔JobTracker║═TaskTrackerį┌▒žę¬Ą─Ģr║“üĒ½@╚ĪŽÓæ¬ą┼ŽóĪŻ
3.Data LOAderŻ║ų„ę¬┬Üž¤╔µ╝░Ė∙ō■ĮoČ©Ą─Ęųģ^keyüĒčb▌döĄō■Ż¼ī”öĄō■▀MąąĘųģ^ĪŻ░³║¼ūį╔Ēā╔éĆų„ę¬HasherŻ║Global Hasher║═Local HasherĪŻ║åå╬ĄžšfŻ¼Hasher¤oĘŪ╩Ū×ķ┴╦ūīĘųģ^Ė³╝ėŠ∙║ŌĪŻ
4.SMS PlannerŻ║SMS╩ŪSQL to MapReduce to SQLĄ─┐sīæĪŻHadoopDB═©▀^╩╣╦¹éā─▄ł╠ąąSQLšłŪ¾üĒ╠ß╣®ę╗éĆ▓óąą╗»öĄō■ÄņŪ░Č╦ū÷öĄō■╠Ä└ĒĪŻSMS╩ŪöUš╣┴╦HiveĪŻĻPė┌Hive╬ęį┌▀@└’▓╗š╣ķ_ĮķĮB┴╦ĪŻ┐éų«╩ŪĻPė┌ę╗ĘN╚┌╚ļĄĮMapReduce jobā╚Ą─SQLĄ─ūāĘNšZčįŻ¼üĒ▀BĮėHDFSā╚┤µĘ┼╬─╝■Ą─tableĪŻ
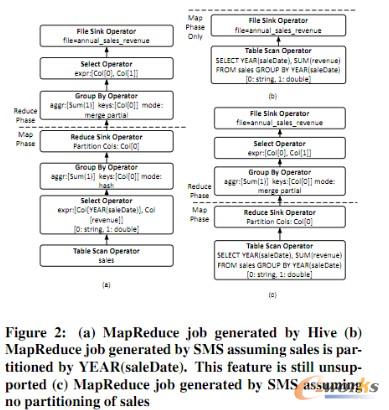
łD3 HadoopDBśŗ│╔▓┐Ęų
5.CoHadoop
šō╬─╠ß│÷CoHadoopüĒĮŌøQHadoop¤oĘ©░čŽÓĻPĄ─öĄō■Č©╬╗ĄĮ═¼ę╗éĆnode╝»║ŽŽ┬Ą─ąį─▄Ų┐ŅiĪŻCoHadoop╩Ūī”HadoopĄ─ę╗éĆ▌p┴┐╝ēöUš╣Ż¼─┐Ą─╩Ūį╩įSæ¬ė├īė─▄┐žųŲöĄō■Ą─┤µā”ĪŻæ¬ė├īė═©▀^─│ĘNĘĮ╩Į╠ß╩ŠCoHadoop─│ą®╝»║Ž└’Ą─╬─╝■╩ŪŽÓĻPąį▒╚▌^┤¾Ą─Ż¼┐╔─▄ąĶę¬║Ž▓óŻ¼ų«║¾CoHadoopŠ═ćLįć╚ź▐DęŲ▀@ą®╬─╝■ęį╠ßĖ▀ę╗Č©Ą─öĄō■ūx╚Īą¦┬╩ĪŻ
5.1 蹊┐ęŌ┴x
Hadoop++ĒŚ─┐ŲõīŹę▓ū÷▀^ŅÉ╦ŲĄ─╩┬Ż¼╦³īó═¼ę╗éĆjob«a╔·Ą─ā╔éĆfile╣▓═¼Ę┼ų├Ż¼Ą½╩Ū«öėąą┬╬─╝■ūó╚ļŽĄĮyĄ─Ģr║“Ż¼╦³ąĶę¬ī”öĄō■ųžą┬ĮM┐ŚĪŻ
CoHadoopĄ─Ė─▀Mų„ę¬ĮoęįŽ┬ÄūéĆ▓┘ū„ĦüĒ┴╦▒╚▌^┤¾Ą─║├╠ÄŻ║╦„ę²Ż©indexingŻ®Ż¼Š█║ŽŻ©groupingŻ®Ż¼Š█╝»Ż©aggregationŻ®Ż¼┐vŽ“┤µā”Ż©columnar storageŻ®Ż¼║Ž▓óŻ©joinŻ®ęį╝░sessionizationĪŻČ°Ž±╚šųŠĘų╬÷▀@śėĄ─▓┘ū„Ż¼╔µ╝░ĄĮĄ─Š═╩Ū░čę╗ą®ģó┐╝öĄō■║Ž▓óŲüĒ╗“š▀▀MąąsessionizationĪŻ▀@┐╔ęį¾w¼FCoHadoopĄ─Ė─▀MęŌ┴x╦∙į┌ĪŻ
ęįŽ┬╩ŪpaperĻPė┌CoHadoopĄ─┐éĮYŻ║
▀@╩Ūę╗ĘN║▄ņ`╗ŅŻ¼äėæBŻ¼▌p┴┐╝ēĄ─╣▓ų├ŽÓĻPöĄō■╬─╝■Ą─ĘĮ░ĖŻ¼Č°Ūę╩Ūų▒Įėį┌HDFS╔ŽīŹ¼FĄ─ĪŻ
į┌╚šųŠ╠Ä└ĒĘĮ├µŻ¼┤_Č©┴╦ā╔éĆė├└²Ż║join║═sessionizationŻ¼╩╣Ą├į┌▓ķįā╠Ä└ĒĘĮ├µĄ├ĄĮ┴╦’@ų°Ą─ąį─▄╠ßĖ▀ĪŻ
ū„š▀▀Ć蹊┐┴╦CoHadoopĄ─╚▌ÕeŻ¼Ęų▓╝╩ĮöĄō■║═öĄō■üG╩¦ĪŻ
į┌▓╗═¼Ą─ł÷Š░Ž┬£yįć┴╦join║═sessionizationĄ─ą¦╣¹ĪŻ
ĮėŽ┬üĒ▀Ć╩ŪĮķĮBŽ┬CoHadoopĄ─įOėŗ╦╝ŽļĪŻ
5.2 Ė─▀MįOėŗĮķĮB
HDFS▒Š╔Ē┤µöĄō■Ą─Ģr║“╩Ūėą╚▀ėÓĄ─ĪŻ─¼šJ╩Ū┤µ╚²Ęų┐ĮžÉĪŻ▀@╚²Ę▌Å═ųŲŲĘĢ■┤µį┌▓╗═¼Ą─ĄžĘĮĪŻūŅ║åå╬╩Ū┤µį┌datanode└’ĪŻ─¼šJĄ─┤µĘ┼ĘĮ╩Į╩ŪĄ┌ę╗Ę▌┐ĮžÉ┤µį┌ą┬Į©Ą─▒ŠĄžšQ╔·Ą─nodeĄ─block└’Ż©╝┘įOūŃē“┤µŻ®Ż¼▀@Įąīæ“ėH║═”Ż©write affinityŻ®ĪŻHDFS╚╗║¾▀xō±═¼ę╗ÖC╝▄╔ŽĄ─datanode┤µĘ┼Ą┌Č■éĆ┐ĮžÉŻ¼▀xō±▓╗═¼ÖC╝▄╔ŽĄ─ę╗éĆdatanode┤µĄ┌╚²Ę▌┐ĮžÉĪŻ▀@╩ŪHDFSĄ─▒ŠüĒĄ─ÖCųŲĪŻ─Ū├┤×ķ┴╦īŹ¼FŽÓĻPöĄō■Ą─╣▓ų├┤µā”Ż¼šō╬─ą▐Ė─┴╦┤µĘ┼▓▀┬įĪŻ
ęį╔ŽHadoop¼FėąĄ─┤µĘ┼▓▀┬įų„ę¬╩Ū×ķ┴╦žō▌dŠ∙║ŌŻ¼Ą½╩Ū«öæ¬ė├ąĶę¬Å─▓╗═¼Ą─╬─╝■└’╚ź╚Ī╦∙ąĶĄ─öĄō■Ą─Ģr║“Ż¼╚ń╣¹─▄ūįČ©┴xę╗ą®▓▀┬įŻ¼─Ū┐╔─▄Ģ■Ą├ĄĮ’@ų°Ą─╠ß╔²ĪŻ▌p┴┐╝ēĄ─CoHadoop╩╣Ą├ķ_░lūįČ©┴xĄ─▓▀┬įūāĄ├║åå╬ĪŻļm╚╗Ęųģ^į┌Hadoop└’īŹ¼F║▄║åå╬Ż¼Ą½╩Ū╣▓ų├▓ó▓╗╚▌ęūŻ¼Hadoopę▓ø]ėą╠ß╣®▀@śėŅÉ╦ŲĄ─┐╔ąąąį╣”─▄īŹ¼FĪŻ
łD4 CoHadoopĄ─öĄō■┤µĘ┼╩ŠęŌłD
╚ńłD╩ŪCoHadoopĄ─öĄō■┤µĘ┼╩ŠęŌłDĪŻCoHadoopöUš╣┴╦HDFSŻ¼╠ß│÷┴╦ą┬Ą─╬─╝■īėī┘ąį——locatorŻ¼▓óŪęą▐Ė─┴╦HadoopĄ─öĄō■┤µĘ┼▓▀┬įęį╩╣ė├▀@éĆlocatorĪŻ╝┘įO├┐éĆlocatorė╔ę╗éĆš¹öĄųĄ▒Ē╩ŠŻ©ę▓┐╔ęį╩ŪäeĄ─▒Ē╩ŠĘĮĘ©Ż®Ż¼─Ū├┤╬─╝■║═locatorų«ķg┐╔ęį╩Ūę╗éĆNŻ║1Ą─ĻPŽĄĪŻ├┐éĆHDFSĄ─╬─╝■ūŅČÓ║═ę╗éĆlocatorĻP┬ōŻ¼═¼ę╗éĆlocator┐╔ęįĻP┬ō║▄ČÓ╬─╝■ĪŻ═¼ę╗éĆlocatorŽ┬Ą─╬─╝■┤µį┌═¼ę╗éĆdatanode╝»║Ž└’Ż¼Č°ø]ėąlocatorė│╔õĄ─╬─╝■ę└┼f░┤šš─¼šJĄ─HadoopĄ─┤µā”ÖCųŲ┤µĘ┼ĪŻłDųąĄ─A║═BŠ═ī┘ė┌═¼ę╗éĆlocatorŻ¼A╬─╝■Ą─ā╔ēKblock║═B╬─╝■Ą─╚²ēKBlockĮY╣¹┤µį┌┴╦═¼ę╗éĆdatanode╝»║Ž└’ĪŻ
×ķ┴╦Ė³║├Ąž╣▄└Ē║═Ė·█Ö▀@ą®locator║═╬─╝■ų«ķgĄ─ė│╔õą┼ŽóŻ¼įOėŗ┴╦ę╗éĆą┬Ą─öĄō■ĮYśŗ——locatortable┤µį┌namenode└’ĪŻ╦³┤µĘ┼┴╦├┐éĆlocatorė│╔õĄ─╬─╝■╝»ĪŻłDųąę▓┐╔ęį┐┤ĄĮĪŻ«önamenode▀\ąąĄ─Ģr║“Ż¼locator table╩Ūį┌ā╚┤µ└’äėæBŠSūoĄ─ĪŻ
ĻPė┌öĄō■┤µĘ┼▓▀┬įĄ─ą▐Ė─╩Ū▀@├┤ū÷Ą─Ż║ų╗ę¬ėąę╗éĆą┬Ą─║═locator lĻP┬ōĄ─╬─╝■f▒╗äōĮ©Ż¼Ģ■╚źlocator table└’▓ķįā╩Ūʱ┤µį┌ę╗éĆīŹ└²╩Ūī┘ė┌▀@éĆlocator lĄ─ĪŻ╚ń╣¹▓╗┤µį┌Ż¼Š═ą┬į÷ę╗ŚlŻ©lŻ¼fŻ®į┌table└’Ż¼▓óė├HDFS─¼šJĄ─┤µĘ┼ĘĮ╩Į┤µ▀@Ę▌╬─╝■Ą─┐ĮžÉéāĪŻ╚ń╣¹ęčĮø┤µį┌Ż¼Š═┐╔ęįų¬Ą└▀@éĆlė│╔õĄ─file listŻ¼╚ń╣¹Å─¼FėąĄ─┤µĘ┼┴╦▀@éĆlistā╚Ą─╬─╝■Ą─réĆdatanode└’░┤ę╗Č©ĘĮ╩ĮŻ©┐╝æ]┐šķgŻ®▀x│÷ÄūéĆė├ė┌┤µą┬üĒĄ─╬─╝■Ą─┐ĮžÉĄ─╣سcŻ¼┤µĘ┼▀@Ę▌╬─╝■Ą─┐ĮžÉéāĪŻ┤¾ų┬Ą─ęŌ╦╝Š═╩Ū▀@śėĪŻ
ĻPė┌╚šųŠĄ─join║═sessionizationĄ─Ė─▀MŻ¼Š═▓╗š╣ķ_┴╦ĪŻ║åå╬┘Nā╔éĆłDĪŻ
łD5 ╚šųŠjoinĄ─Ė─▀M
łD6 ╚šųŠsessionizationĄ─Ė─▀M
ū÷sessionizationŻ¼ī”ė┌╚šųŠ╠Ä└ĒĢr║“MapReduceėŗ╦ŃĄ─ė░Ēæ▒╚▌^ĪŻ
6.┐éĮY
ļm╚╗╬ęī”HadoopėąØŌ║±Ą─┼d╚żŻ¼Ą½╩Ūūį╝║╦∙─▄Įėė|ĄĮĄ─ĒŚ─┐║═ŁhŠ│Ż¼Č╝ø]ėąĄĮ▀_ę╗éĆ▒╚▌^’¢║═Ą─ąĶŪ¾³cĪŻę¬ū÷Ęų▓╝╩Į┤µā”Ż┐Ė∙▒Šė├▓╗ų°äėė├HBase╗“š▀äeĄ─NoSQLĮM│╔Ą─Ęų▓╝╩Į╝»╚║Ż¼ų╗ąĶę¬ę╗éĆĘų▓╝╩ĮĄ─MySQL╝»╚║Š═┐╔ęį┴╦Ż¼NoSQL┐╔ęįū÷Ą─╩┬Ż¼ŲõīŹMySQL║╬ćL▓╗─▄═Ļ│╔Ż┐ų╗╩ŪšfNoSQLī”─│ą®öĄō■Ą─┤µā”Ż¼į┌─│ą®ūxīæąį─▄╔ŽėąŠų▓┐Ą─éĆąį╗»Ą─ā×ä▌Č°ęčĪŻĖ³▓╗▒žšfę¬ė├MapReduce╚ź═Ļ│╔╩▓├┤śė┤¾ęÄ─ŻŻ¼TB╝ēöĄō■Ą─Ęų▓╝╩Į▓óąąėŗ╦Ń┴╦ĪŻį┌öĄō■║═ė▓╝■įO╩®ĘĮ├µŻ¼ęįų┴ĄĮ╝╝ąg│╠Č╚ĘĮ├µŻ¼īWąŻ└’Č╝ø]ėąØMūŃŚl╝■Ż¼ø]ėą╚ń┤╦Ą─ąĶŪ¾ĪŻ
īWąŻĄ─šn│╠└’ę▓ø]ėą╔µ╝░ĄĮĘų▓╝╩ĮĄ─ā╚╚▌ĪŻĘų▓╝╩Į╬─╝■ŽĄĮy/┤µā”/╦„ę²ų«ŅÉĄ─įÆŅ}ę╗ų▒╩Ū┤µį┌ė┌Ų¾śI╝ēäeŻ¼┤µį┌ė┌┤¾╣½╦Š┤¾öĄō■╗∙ĄA║═Ę■äšŲ„╝»╚║╗∙ĄAĄ─ĪŻīWąŻ└’┼╝Ā¢┐╔ęį┬ĀĄĮ╚ń░ó└’ķ_Ą─ĻPė┌Ęų▓╝╩ĮĄ─ųvū∙Ż¼ę▓╩Ū║▄╗∙ĄAĄ─Ż¼£\ćLĮžų╣ĪŻ
│÷╔·į┌╩▓├┤śėĄ──Ļ┤·Ż¼Š═Ģ■Įėė|╩▓├┤śėĄ─╝╝ągĪŻīW┴Ģ╩▓├┤śėĄ─╝╝ągŻ¼Š═─▄│õīŹūį╝║│╔╩▓├┤śėĄ─╝╝ąg╚╦▓┼ĪŻ░č╬šHadoopŻ¼░č╬šĢr┤·Ą─║╦ą─╝╝ągŻ¼Š═šŲ╬š┴╦¼Fį┌┤¾öĄō■Ģr┤·Ż¼╔§ų┴┐╔ęįė÷ęŖ▓ó▓┘┐ž╬┤üĒŻĪ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.vmgcyvh.cn/
▒Š╬─ś╦Ņ}Ż║Hadoop Ą─Ęų▓╝╩Į╝▄śŗĖ─▀M┼cæ¬ė├
▒Š╬─ŠWųĘŻ║http://www.vmgcyvh.cn/html/support/11121511713.html