▒│Š░ą┼Žó
ĪĪĪĪeBay╣½╦Š«öŪ░├µ┼RĄ─ų„ę¬╠¶æį┌ė┌Ż¼öĄō■ęÄ─Żš²ļSų°ė├æ¶╚║¾wĄ─ČÓśė╗»═žš╣Č°╦«Øq┤¼Ė▀ĪŻ╬ęéāĄ─ė├涗—▒╚╚ńį┌Ęų╬÷┼cśIäš▓┐ķT«öųąŽŻ═¹─▄į┌▒Ż│ųūŅĄ═čė▀t╦«ŲĮĄ─Ū░╠ߎ┬└^└m╩╣ė├ūį╝║╦∙╩ņŽżĄ─╣żŠ▀ĘĮ░ĖŻ¼└²╚ńTableau┼cExcelĪŻ
ĪĪĪĪėąĶbė┌┤╦Ż¼╬ęéā┼c╣½╦Šā╚▓┐Ą─Ęų╬÷▓┐ķT▀MąąŠo├▄║Žū„Ż¼▓ó╣┤└š│÷eBayč█ųąūŃęįśŗ│╔│╔╣”«aŲĘĄ─╗∙▒Šę¬Ū¾Ż║
1.öĄ░┘ā|öĄō■ąąĄ─▓ķįāčė▀tąĶę¬▒Ż│ųį┌┤╬├ļ╝ēäeĪŻ
2.─▄ē“×ķ╩╣ė├SQL╝µ╚▌ąį╣żŠ▀Ą─ė├æ¶╠ß╣®ANSI SQLĪŻ
3.═Ļš¹Ą─OLAPĘĮ░ĖęįīŹ¼FĖ„ŅÉĖ▀╝ē╣”─▄ĪŻ
4.ōĒėąī”Ė▀╗∙öĄ┼c│¼┤¾ęÄ─ŻśIäš¾wŽĄĄ─ų¦│ų─▄┴”ĪŻ
5.├µŽ“│╔Ū¦╔Ž╚fė├æ¶Ą─Ė▀▓ó░ląį╠Ä└Ē─▄┴”ĪŻ
6.─▄ē“╠Ä└ĒTB─╦ų┴PB╝ēäeĘų╬÷╚╬䚥─Ęų▓╝╩ĮÖMŽ“öUš╣╝▄śŗĪŻ
ĪĪĪĪ╬ęéā║▄┐ņęŌūRĄĮŻ¼ø]ėą╚╬║╬ę╗ĘN═Ō▓┐ĮŌøQĘĮ░Ė─▄ē“ŪąīŹØMūŃ╬ęéāĄ─Š▀¾wę¬Ū¾——╠žäe╩Ūį┌ķ_į┤Hadoop╔ńģ^«öųąĪŻ×ķ┴╦ĮŌøQŲ¾śIśIäš├µ┼RĄ─▀@ę╗ŽĄ┴ąŠo╝▒ĀŅørŻ¼╬ęéāøQČ©Å─┴Ńķ_╩╝ūįų„┤“įņę╗╠ūŲĮ┼_ĪŻį┌ā׹ѥ─╝╝ągłFĻĀ┼c▓┐Ęųįć³c┐═æ¶Ą─═©┴”┼õ║Žų«Ž┬Ż¼╬ęéāęčĮø─▄ē“į┌īóKylinŲĮ┼_ę²╚ļ╔·«aŁhŠ│Ą─═¼ĢrĪó×ķŲõ░l▓╝ę╗╠ūķ_į┤░µ▒ŠĪŻ
ųž³c╠žąįĖ┼╩÷
ĪĪĪĪKylin ╩Ūę╗╠ūū┐įĮĄ─ŲĮ┼_ĘĮ░ĖŻ¼─▄ē“į┌┤¾öĄō■Ęų╬÷ŅIė“īŹ¼FęįŽ┬Ė„ĒŚ╠žąįŻ║
• ęÄ─Ż╗»ŁhŠ│Ž┬Ą─śO╦┘OLAPę²ŪµŻ║KylinĄ─įOėŗ─┐Ą─į┌ė┌Ž„£pHadoopŁhŠ│ųą╠Ä└Ē│¼▀^░┘ā|ąąöĄō■ĢrĄ─▓ķįāčė▀tĢrķgĪŻ
• Hadoop╔ŽĄ─ANSI SQLĮė┐┌Ż║Kylin─▄ē“į┌Hadoopų«╔Ž╠ß╣®ANSI SQL▓óų¦│ų┤¾▓┐ĘųANSI SQL▓ķįā╣”─▄ĪŻ
•Į╗╗ź╩Į▓ķįā╣”─▄Ż║ė├æ¶┐╔ęį═©▀^Kylinęį├ļ╝ēęįŽ┬čė▀t╦«ŲĮīŹ¼F┼cHadoopöĄō■Ą─Į╗╗ź——į┌├µī”═¼ę╗╠ūöĄō■╝»ĢrŻ¼Ųõąį─▄▒Ē¼Fā×ė┌Hive▓ķįāÖCųŲĪŻ
• └¹ė├MOLAP cubeŻ©┴óĘĮ¾wŻ®ī”öĄ░┘ā|ąąöĄō■▀Mąą▓ķįāŻ║ė├æ¶─▄ē“į┌Kylin«öųąČ©┴xę╗╠ūöĄō■─Żą═ī”Ųõ▀MąąŅAśŗĮ©Ż¼Ųõųą╦∙─▄░³║¼Ą─įŁ╩╝öĄō■ėøõø┐╔│¼▀^░┘ā|ąąĪŻ
• ┼c╔╠äšųŪ─▄╣żŠ▀▀Mąą¤o┐p╗»╝»│╔Ż║Kylin─┐Ū░─▄ē“┼cČÓĘN╔╠äšųŪ─▄╣żŠ▀ŽÓ╝»│╔Ż¼░³└©Tableauęį╝░Ųõ╦³Ą┌╚²ĘĮæ¬ė├│╠ą“ĪŻ
• ķ_į┤ODBC“īäė│╠ą“Ż║KylinĄ─ODBC“īäė│╠ą“Å─┴Ńķ_╩╝ų▓ĮśŗĮ©Č°│╔Ż¼Č°Ūę─▄ē“┼cTableauīŹ¼F┴╝║├Ą─ģfū„ą¦╣¹ĪŻ╬ęéāę▓ęčĮøī”▀@▓┐Ęų“īäė│╠ą“▀Mąąķ_į┤╠Ä└Ē▓ó░l▓╝ų┴╝╝ąg╔ńģ^«öųąĪŻ
Ųõ╦³╠žąįŻ║
- ╚╬äš╣▄└Ē┼c▒O┐žÖCųŲ
- ═©▀^ē║┐s┼cŠÄ┤aÖCųŲĮĄĄ═┤µā”╚▌┴┐ąĶŪ¾
- cubeĄ─į÷┴┐╩ĮĖ³ą┬
- └¹ė├HBaseģf╠Ä└ĒŲ„īŹ¼F▓ķįāčė▀t┐žųŲ
- ī”▓╗═¼ėŗöĄ▀MąąĮ³╦Ų▓ķįāĄ──▄┴”Ż©HyperLogLogŻ®
- ╠ß╣®ęūė┌╩╣ė├Ą─WebĮń├µŻ¼ų╝į┌ī”cube▀Mąą╣▄└ĒĪóśŗĮ©Īó▒O┐ž┼c▓ķįā
- cube/ĒŚ─┐īė├µī”ACL▀MąąįOų├Ą─░▓╚½╣”─▄
- ų¦│ųLDAP╝»│╔
╗∙▒ŠįOėŗ╦╝┬Ę
ĪĪĪĪKylinŲĮ┼_Ą─įOėŗ╦╝┬ĘŲõīŹ▓óĘŪ╚½ą┬«a╔·ĪŻį┌▀^╚ź╚²╩«─Ļ«öųąŻ¼ęčĮøėą║▄ČÓ╝╝ągĘĮ░Ė╩╣ė├ĄĮ═¼śėĄ─└Ēšōę└ō■üĒīŹ¼FĘų╬÷┴„│╠╝ė╦┘ĪŻŠ▀¾wČ°čįŻ¼┤╦ŅÉ╝╝ąg░³└©īóŅAŽ╚ėŗ╦Ń═Ļ│╔Ą─ĮY╣¹▒Ż┤µŲüĒęįéõĘų╬÷▓ķįāĪó└¹ė├╦∙ėą┐╔─▄Ą─ŠSČ╚ĮM║Ž×ķ├┐éĆīė╝ē╔·│╔cuboidŻ©╗∙▒ŠĘĮ¾wŻ®Īó╗“š▀╩Ūį┌▓╗═¼īė╝ē╔Žī”╚½▓┐ųĖöĄ▀Mąąėŗ╦ŃĪŻ
ĪĪĪĪŽ┬├µ▀@Ę∙łDŲ¼╦∙╩Š×ķcuboidĄ─═žōõĮYśŗŻ¼╣®┤¾╝ęė├ū„ģó┐╝Ż║
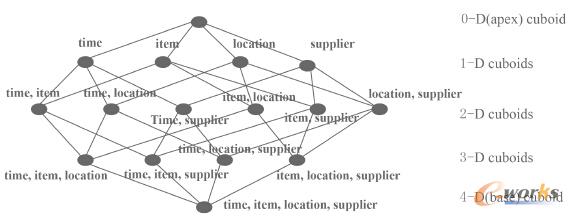
łD1 cuboidĄ─═žōõĮYśŗ
«ööĄō■ęÄ─ŻūāĄ├įĮüĒįĮ┤¾ĢrŻ¼ŅAėŗ╦Ń╠Ä└ĒÖCųŲŠ═Ģ■ūāĄ├¤oĘ©īŹ¼F——╝┤╩╣ė▓╝■ąį─▄į┘ÅŖ┤¾ę▓ė┌╩┬¤očaĪŻ▓╗▀^į┌HadoopÅŖ┤¾Ą─Ęų▓╝╩Įėŗ╦Ń─▄┴”ų¦│ųŽ┬Ż¼ėŗ╦Ń╚╬äš─▄ē“ĮĶų·│╔░┘╔ŽŪ¦éĆėŗ╦Ń╣سcĄ─┐é¾w┘Yį┤ĪŻ▀@Š═▒ŻūC┴╦Kylin─▄ē“ęį▓ó░lĘĮ╩Įī”▀@ą®ėŗ╦Ń╚╬äš▀Mąą╠Ä└ĒŻ¼▓ó═©▀^║Ž▓ó╔·│╔ūŅĮKĮY╣¹——▀@─▄ē“’@ų°ĮĄĄ═š¹¾w╠Ä└ĒĢrķgĪŻ
Å─ĻPŽĄą═ĄĮµI-ųĄą═
ĪĪĪĪŽ┬├µ┼eę╗éĆīŹ└²Ż¼╝┘įOHive▒Ē«öųą╦∙▒Ż┤µĄ─ÄūŚlėøõø┤·▒Ēų°ę╗╠ūĻPŽĄą═ĮYśŗĪŻ«öŲõöĄō■ęÄ─Żį÷ķLĄĮśOŲõŠ▐┤¾Ą─╦«ŲĮĢr——└²╚ń╔Ž░┘ā|╔§ų┴▀^╚fā|ąąöĄō■——─Ū├┤Ž±“2010─Ļ╬ęéāį┌├└ć°▒Š═┴╩█│÷┴╦ČÓ╔┘╠ū╝╝ągŅÉĘĮ░Ė”▀@śėĄ─║åå╬å¢Ņ}ę▓īóĦüĒ║Ł╔wŠ▐┤¾öĄō■┴┐Ą─▒Ēā╚╚▌Æ▀├ĶŻ¼Įo│÷æ¬┤Ą─čėĢrĀŅørę▓Ģ■ūāĄ├¤oĘ©Įė╩▄ĪŻė╔ė┌├┐ę╗┤╬▀\ąą▓ķįāĢr╦∙ąĶꬥ─ųĄ╩Ū╣╠Č©Ą─Ż¼ę“┤╦╬ęéā═Ļ╚½┐╔ęįŅAŽ╚▀Mąąėŗ╦Ń▓óī”ĮY╣¹╝ėęį┤µā”Īóęįéõ╚š║¾ļSĢrš{ė├ĪŻ▀@ĒŚ╝╝ąg▒╗ĘQ×ķÅ─ĻPŽĄą═ĄĮµI-ųĄą═Ż©Relational to Key—ValueŻ¼║åĘQKVŻ®╠Ä└ĒĪŻ╠Ä└Ē▀^│╠īó╔·│╔╦∙ėąŠSČ╚ĮM║Ž▓ó╚ńŽ┬łD╦∙╩Šīó£yĄ├ųĄ’@╩Š│÷üĒ——łDŲ¼ėęé╚×ķėŗ╦ŃĮY╣¹ĪŻłDŲ¼Ą─ųąķgę╗┴ąā╚╚▌ė╔ū¾ų┴ėę▒Ē╩ŠĄ─╩Ū▀@ŅÉ┤¾ęÄ─ŻöĄō■╠Ä└Ē┴„│╠ųąöĄō■╩Ū╚ń║╬ė╔Map Reduce▀Mąąėŗ╦ŃĄ─ĪŻ
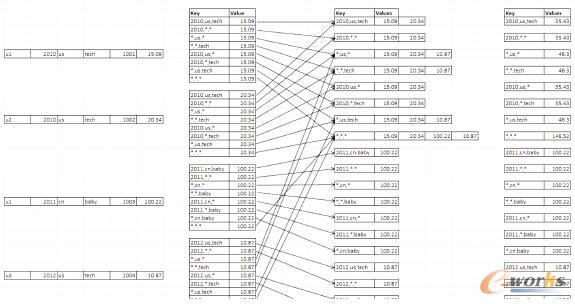
łD2 Map Reduceėŗ╦Ń
KylinĄ─śŗĮ©š²╩Ūęį▀@╠ū└Ēšō×ķ╗∙ĄAŻ¼Č°Ūęį┌ī”┤¾ęÄ─ŻöĄō■▀Mąą╠Ä└ĒĢr│õĘų░lō]┴╦Hadoop╔·æBŽĄĮyĄ─ÅŖ┤¾─▄┴”Ż║
1.Å─Hive«öųąūx╚ĪöĄō■Ż©▀@ą®öĄō■▒╗▒Ż┤µį┌HDFSų«╔ŽŻ®
2.▀\ąąMap Reduce╚╬äšęįīŹ¼FŅAėŗ╦Ń
3.īócubaöĄō■▒Ż┤µį┌HBase«öųą
4.└¹ė├Zookeeper▀Mąą╚╬äšģfš{
╝▄śŗ
ĪĪĪĪęįŽ┬łD▒Ē╦∙╩Š×ķKylinĄ─Ė▀īė╝▄śŗĪŻ

łD3 KylinĄ─Ė▀īė╝▄śŗłD
ęį╔ŽłD▒Ē╣┤└š│÷CubeśŗĮ©ę²ŪµŻ©Cube Build EngineŻ®╩Ū╚ń║╬ęįļxŠĆ╠Ä└ĒĘĮ╩ĮīóĻPŽĄą═öĄō■▐D╗»│╔µI-ųĄą═öĄō■Ą─ĪŻŲõųąĄ─³SŠĆ▓┐Ęų▀Ć▒Ē¼F│÷į┌ŠĆĘų╬÷öĄō■Ą─╠Ä└Ē┴„│╠ĪŻöĄō■šłŪ¾┐╔ęį└¹ė├╗∙ė┌SQLĄ─╣żŠ▀ė╔SQL╠ßĮ╗Č°«a╔·Ż¼╗“š▀└¹ė├Ą┌╚²ĘĮæ¬ė├│╠ą“═©▀^KylinĄ─RESTfulĘ■äšüĒīŹ¼FĪŻRESTfulĘ■äšĢ■š{ė├Query EngineŻ¼║¾š▀ätÖz£yī”æ¬Ą──┐ś╦öĄō■╝»╩ŪʱšµīŹ┤µį┌ĪŻ╚ń╣¹┤_īŹ┤µį┌Ż¼įōę²ŪµĢ■ų▒ĮėįLå¢─┐ś╦öĄō■▓óęį┤╬├ļ╝ēčė▀tĘĄ╗žĮY╣¹ĪŻ╚ń╣¹─┐ś╦öĄō■╝»▓ó▓╗┤µį┌Ż¼įōę²ŪµätĢ■Ė∙ō■įOėŗīó¤oŲź┼õöĄō■╝»Ą─▓ķįā┬Ęė╔ų┴Hadoop╔ŽĄ─SQL╠ÄĪó╝┤Į╗ė╔HiveĄ╚Hadoop╝»╚║žōž¤╠Ä└ĒĪŻ
ęįŽ┬×ķĻPė┌KylinŲĮ┼_ā╚╦∙ėąĮM╝■Ą─įö╝Ü├Ķ╩÷ĪŻ
•į¬öĄō■╣▄└Ē╣żŠ▀Ż©Metadata ManagerŻ®Ż║Kylin╩Ūę╗┐Ņį¬öĄō■“īäėą═æ¬ė├│╠ą“ĪŻį¬öĄō■╣▄└Ē╣żŠ▀╩Ūę╗┤¾ĻPµIąįĮM╝■Ż¼ė├ė┌ī”▒Ż┤µį┌Kylin«öųąĄ─╦∙ėąį¬öĄō■▀Mąą╣▄└ĒŻ¼Ųõųą░³└©ūŅ×ķųžę¬Ą─cubeį¬öĄō■ĪŻŲõ╦³╚½▓┐ĮM╝■Ą─š²│Ż▀\ū„Č╝ąĶęįį¬öĄō■╣▄└Ē╣żŠ▀×ķ╗∙ĄAĪŻ
•╚╬äšę²ŪµŻ©Job EngineŻ®Ż║▀@╠ūę²ŪµĄ─įOėŗ─┐Ą─į┌ė┌╠Ä└Ē╦∙ėąļxŠĆ╚╬䚯¼Ųõųą░³└©shell─_▒ŠĪóJava APIęį╝░Map Reduce╚╬䚥╚Ą╚ĪŻ╚╬äšę²Ūµī”Kylin«öųąĄ─╚½▓┐╚╬äš╝ėęį╣▄└Ē┼cģfš{Ż¼Å─Č°┤_▒Ż├┐ę╗ĒŚ╚╬äšČ╝─▄Ą├ĄĮŪąīŹł╠ąą▓óĮŌøQŲõķg│÷¼FĄ─╣╩šŽĪŻ
•┤µā”ę²ŪµŻ©Storage EngineŻ®Ż║▀@╠ūę²Ūµžōž¤╣▄└ĒĄūīė┤µā”——╠žäe╩ŪcuboidŻ¼ŲõęįµI-ųĄī”Ą─ą╬╩Į▀Mąą▒Ż┤µĪŻ┤µā”ę²Ūµ╩╣ė├Ą─╩ŪHBase——▀@╩Ū─┐Ū░Hadoop╔·æBŽĄĮy«öųąūŅ└ĒŽļĄ─µI-ųĄŽĄĮy╩╣ė├ĘĮ░ĖĪŻKylin▀Ć─▄ē“═©▀^öUš╣īŹ¼Fī”Ųõ╦³µI-ųĄŽĄĮyĄ─ų¦│ųŻ¼└²╚ńRedisĪŻ
•REST ServerŻ║ REST Server╩Ūę╗╠ū├µŽ“æ¬ė├│╠ą“ķ_░lĄ─╚ļ┐┌³cŻ¼ų╝į┌īŹ¼Fßśī”KylinŲĮ┼_Ą─æ¬ė├ķ_░l╣żū„ĪŻ ┤╦ŅÉæ¬ė├│╠ą“┐╔ęį╠ß╣®▓ķįāĪó½@╚ĪĮY╣¹Īóė|░lcubeśŗĮ©╚╬äšĪó½@╚Īį¬öĄō■ęį╝░½@╚Īė├æ¶ÖÓŽ▐Ą╚Ą╚ĪŻ
•ODBC“īäė│╠ą“Ż║×ķ┴╦ų¦│ųĄ┌╚²ĘĮ╣żŠ▀┼cæ¬ė├│╠ą“——└²╚ńTableau——╬ęéāśŗĮ©Ų┴╦ę╗╠ūODBC“īäė│╠ą“▓óī”Ųõ▀Mąą┴╦ķ_į┤ĪŻ╬ęéāĄ──┐ś╦╩Ūūīė├æ¶─▄ē“Ė³×ķĒśĢ│Ąž▓╔ė├▀@╠ūKylinŲĮ┼_ĪŻ
•▓ķįāę²ŪµŻ©Query EngineŻ®Ż║«öcube£╩éõŠ═Šw║¾Ż¼▓ķįāę²ŪµŠ═─▄ē“½@╚Ī▓óĮŌ╬÷ė├æ¶▓ķįāĪŻ╦³ļS║¾Ģ■┼cŽĄĮyųąĄ─Ųõ╦³ĮM╝■▀MąąĮ╗╗źŻ¼Å─Č°Ž“ė├æ¶ĘĄ╗žī”æ¬Ą─ĮY╣¹ĪŻ
ĪĪĪĪį┌Kylin«öųąŻ¼╬ęéā╩╣ė├ę╗╠ū├¹×ķApache CalciteĄ─ķ_į┤äėæBöĄō■╣▄└Ē┐“╝▄ī”┤·┤aā╚Ą─SQLęį╝░Ųõ╦³▓Õ╚ļā╚╚▌▀MąąĮŌ╬÷ĪŻCalcite╝▄śŗ╚ńŽ┬łD╦∙╩ŠĪŻŻ©CalciteūŅ│§▒╗├³├¹×ķOptiqŻ¼ė╔Julian Hyde╦∙ŠÄīæŻ¼Ą½╚ńĮ±ęčĮø│╔×ķApacheʧ╗»Ų„ĒŚ─┐ų«ę╗ĪŻŻ®
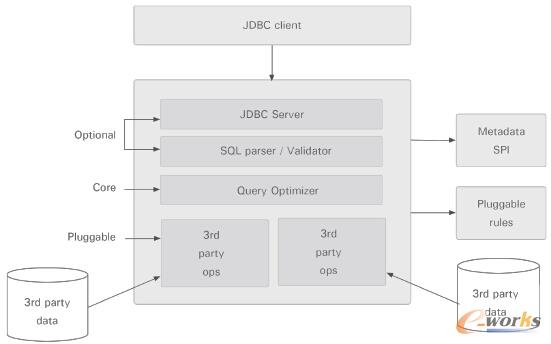
łD4 Calcite╝▄śŗłD
Kylinį┌eBay╣½╦ŠųąĄ─æ¬ė├
ĪĪĪĪį┌ī”Kylin▀Mąąķ_į┤╗»╠Ä└ĒĄ─═¼ĢrŻ¼╬ęéāęčĮøį┌eBay╣½╦ŠĄ─ČÓéĆśIäš▓┐ķT«öųąīóŲõæ¬ė├ė┌╔·«aīŹ█`ĪŻŲõųąęÄ─ŻūŅ┤¾Ą─ė├└²Š═╩Ūī”ė╔120ČÓā|Ślį┤ėøõø╦∙╔·│╔Ą─│¼▀^14TB cubeöĄō■▀MąąĘų╬÷ĪŻ90%Ą─▓ķįāšłŪ¾Č╝─▄į┌5├ļńŖų«ā╚½@╚ĪĄĮĘĄ╗žĮY╣¹ĪŻ¼Fį┌Ż¼╬ęéāōĒėąĖ³ČÓ├µŽ“Ęų╬÷Ĥęį╝░śIäšė├æ¶Ą─ė├└²Ż¼╦¹éā─▄ē“įLå¢▀@ą®Ęų╬÷ÖCųŲ▓ó▌p╦╔═©▀^Tableauāx▒Ē░Õ½@╚ĪŽÓĻPĮY╣¹——Č°▓╗į┘ąĶę¬ĮĶų·Hive▓ķįā╗“š▀shell├³┴ŅĄ╚Å═ļsÖCųŲĪŻ
Ž┬ę╗▓Į░lš╣ęÄäØ
• į┌Ė▀╗∙öĄŠSČ╚╔Žų¦│ųTopN╦ŃĘ©Ż©╝┤ī”┤¾┴┐ī”Ž¾▀Mąą┼┼ą“▓óÅ─ųą▀x╚ĪŪ░N╬╗ĮY╣¹Ż®Ż║─┐Ū░Ą─MOLAP╝╝ągį┌Ė▀╗∙öĄŠSČ╚╔Ž▀Mąą▓ķįāĢrĄ─▒Ē¼F╔ą╦Ń▓╗╔Ž═Ļ├└——└²╚ńī”å╬ę╗┴ąųąĄ─öĄ░┘╚féĆ▓╗═¼ųĄ▀MąąTopN▀\╦ŃĪŻ
┼cĖ„ŅÉ╦č╦„ę²ŪµŅÉ╦ŲŻ©š²╚ń▒ŖČÓ蹊┐╚╦åT╦∙ųĖ│÷Ż®Ż¼Ą╣┼┼╦„ę²╩Ū┤╦ŅÉŅAśŗĮ©ĮY╣¹Ą─└ĒŽļŲź┼õÖCųŲĪŻ
• ų¦│ų╗ņ║ŽOLAP(║åĘQHOLAP)Ż║MOLAPį┌Üv╩ĘöĄō■▓ķįāŅIė“ōĒėą│÷╔½Ą─īŹļH▒Ē¼FŻ¼Ą½ė╔ė┌įĮüĒįĮČÓöĄō■ąĶę¬ęįīŹĢrĘĮ╩Į╝ėęį╠Ä└ĒŻ¼ę“┤╦╬ęéāąĶę¬▒M┐ņīóīŹĢr/Į³īŹĢr╠Ä└ĒĮY╣¹┼cÜv╩ĘĮY╣¹ĮY║ŽŲüĒĪóęįū„×ķśIäšøQ▓▀ųąĄ─ģó┐╝ą┼ŽóĪŻ║▄ČÓā╚┤µā╚╝╝ągĘĮ░ĖęčĮø─▄ē“ęįĻPŽĄą═OLAPŻ©║åĘQROLAPŻ®Ą─ĘĮ╩ĮØMūŃ╔Ž╩÷ąĶŪ¾ĪŻČ°KylinĄ─Ž┬ę╗┤·░µ▒Šīó│╔×ķ╗ņ║ŽOLAPŻ©║åĘQHOLAPŻ®Ż¼╝┤ĮY║ŽMOLAP┼cROLAPļpĘĮĄ─ā×ä▌ęįĦüĒå╬ę╗ę╗╠ū├µŽ“Ū░Č╦▓ķįāĄ─╚ļ┐┌³cĘĮ░ĖĪŻ
ķ_į┤
ĪĪĪĪKylinęčĮøęįķ_į┤ū╦æB▒╗Į╗ĖČų┴╝╝ąg╔ńģ^ĪŻ×ķ┴╦ęįKylin×ķ║╦ą─░lš╣│÷Ė³×ķÅŖ┤¾Ą─╔·æBŽĄĮyŻ¼╬ęéā─┐Ū░š²╠ßūhīóKylin▐D╗»×ķApacheʧ╗»Ų„ĒŚ─┐ĪŻį┌Owen O’MalleyŻ©Hortonworks╣½╦Š┬ō║Žäō╩╝╚╦╝µApache│╔åTŻ®┼cJulian HydeŻ©Apache CalciteŠåįņš▀Ż¼─┐Ū░╣®┬Üė┌Hortonworks╣½╦ŠŻ®Ą╚Hadoopķ_░lš▀╔ńģ^ų¦│ųš▀Ą─Č”┴”ģfų·Ż¼╬ęéāŽÓą┼KylinūŃęį│╦ķ_į┤╔ńģ^▀@╣╔ÅŖä┼Ą─¢|’LĒś└¹┐ń╚ļą┬Ą─╝oį¬ĪŻ
ĪĪĪĪū„×ķŲ▓ĮŻ¼┤¾╝ę▓ó▓╗ę╗Č©±R╔ŽŠ═ę¬ī”║╦ą─┤·┤aÄņ▀Mąąķ_į┤žĢ½IŻ¼Å─ęįŽ┬ĘĮ├µų°╩ųę▓╩Ū▓╗ÕeĄ─▀xō±Ż║
1.Shell┐═æ¶Č╦
2.RPCĘ■äšŲ„
3.╚╬äšš{Č╚
4.╣żŠ▀
┐éĮY
ĪĪĪĪKylinęčĮøį┌eBay╣½╦Šā╚▓┐╚┌╚ļ╔·«aŁhŠ│Ż¼īŻķTžōž¤╠Ä└ĒęÄ─ŻśOČ╦²ŗ┤¾Ą─öĄō■╝»ĪŻ▀@╠ūŲĮ┼_ōĒėą’@ų°Ą─ąį─▄ā×ä▌Ż¼īŹ█`ūC├„Ųõ─▄ē“Ä═ų·Ęų╬÷Ĥéā▌p╦╔ĮĶų·ūį╝║╦∙×ķ╩ņŽżĄ─╣żŠ▀ī”Hadoop«öųąĄ─öĄō■▀Mąą│õĘų└¹ė├ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.vmgcyvh.cn/
▒Š╬─ś╦Ņ}Ż║Kylinš²╩Į░l▓╝Ż║├µŽ“┤¾öĄō■Ą─ĮKśOOLAPę²ŪµĘĮ░Ė
▒Š╬─ŠWųĘŻ║http://www.vmgcyvh.cn/html/support/11121517189.html